
15: DINO: Self-Distillation with No Labels
Self-supervised learning meets vision transformers, and the rest is history


Introduction
In the previous episodes of the self-supervised learning (SSL) series, we talked about SimCLR and BYOL, two famous approaches to image representation learning that rely on convolutional neural networks (CNNs) and clever data augmentation strategies.
However, when a new kid is in town, methods also need to adapt. “Emerging Properties in Self-Supervised Vision Transformers” by Meta AI, better known as DINO [1], questions if the recently proposed Vision Transformer (ViT) behaves differently compared to classical convolutional networks when trained in a self-supervised manner. The answer, as it turns out, is a resounding yes!
Experimental results not only confirm that adapting self-supervised methods to this architecture works particularly well but also show that features from self-supervised ViT contain explicit information about the semantics of an image, which does not emerge as clearly with supervised ViTs or with convnets. Let’s dive in.
ViT Recap
This may be a good time to recap how a Vision Transformer [2] works, as from now on, SSL is all about that with no turning back. At a high level, ViT adapts the transformer architecture originally designed for language with minimal modifications.
The first step, after resizing an input image to a fixed resolution (e.g., 224×224), is to divide it into fixed-size patches, typically 16×16 pixels each. These patches are then flattened and linearly projected into embedding vectors. In practice, this projection is efficiently implemented using a single convolutional layer with both the kernel size and stride equal to the patch size, for example, mapping a 16×16×3 patch to a 768-dimensional embedding.
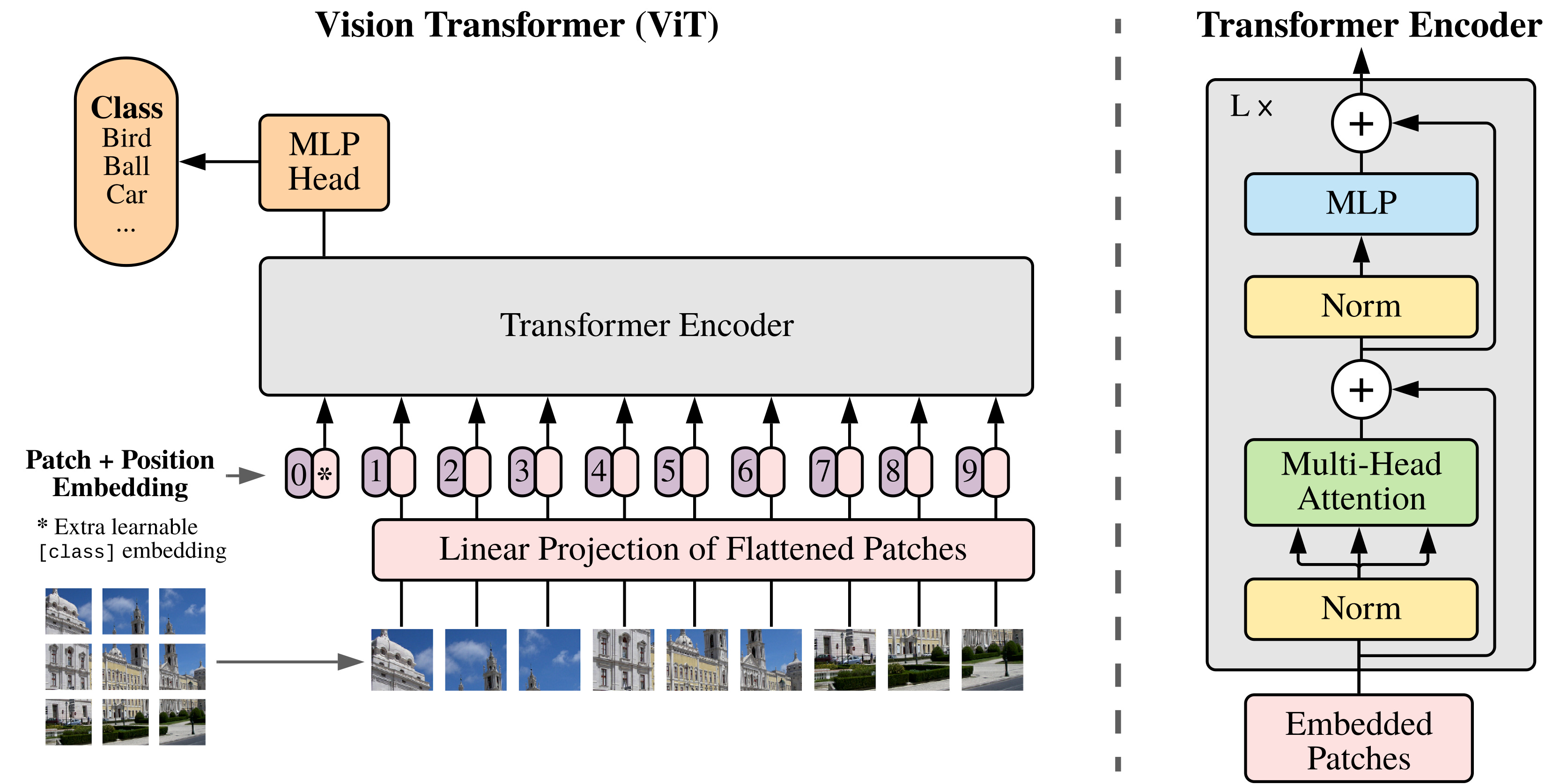
To this sequence of patch embeddings, the original ViT prepends a [CLS] token, which acts as a summary representation of the entire image. Rather than promoting one of the image patches to a special role, ViT introduces this dedicated token from the start and later uses it, for example, in classification tasks. Each embedding is also enriched with positional encodings so the model retains spatial information of where the patches came from in the image.
From this point on, it no longer matters whether the transformer is processing image patches, words, audio segments, or any other type of tokenized input: the core architecture remains unchanged, which is exactly what makes it so universally applicable. A few dozen blocks later, the model has built rich contextualized representations by capturing relationships across the entire patch sequence and compressing that information into the final [CLS] embedding.
Back to DINO: Architecture and Training
Now that we’ve brushed up on how Vision Transformers work, let’s turn our focus back to DINO. Similar in spirit to BYOL, the previous state-of-the-art from DeepMind, DINO also follows a student–teacher framework consisting of two networks: a student that is actively trained and a teacher that is not directly optimized but updated through an exponential moving average of the student’s parameters.
However, DINO simplifies the architecture even further. Unlike BYOL, it removes the need for an extra prediction head, resulting in the same design for student and teacher networks. That consists of an image encoder (ViT or ResNet) plus a projection head, which is thrown away at the end, consisting of an MLP and normalization.
The always-present danger of representation collapse is prevented using two tricks: centering the teacher output by subtracting the mean computed over the batch and sharpening by dividing the sotfmax logits by a temperature T < 1. Also, DINO uses cross-entropy to align the student and teacher output distribution instead of mean squared error or cosine similarity. Enough technical details: let’s see how it is trained!
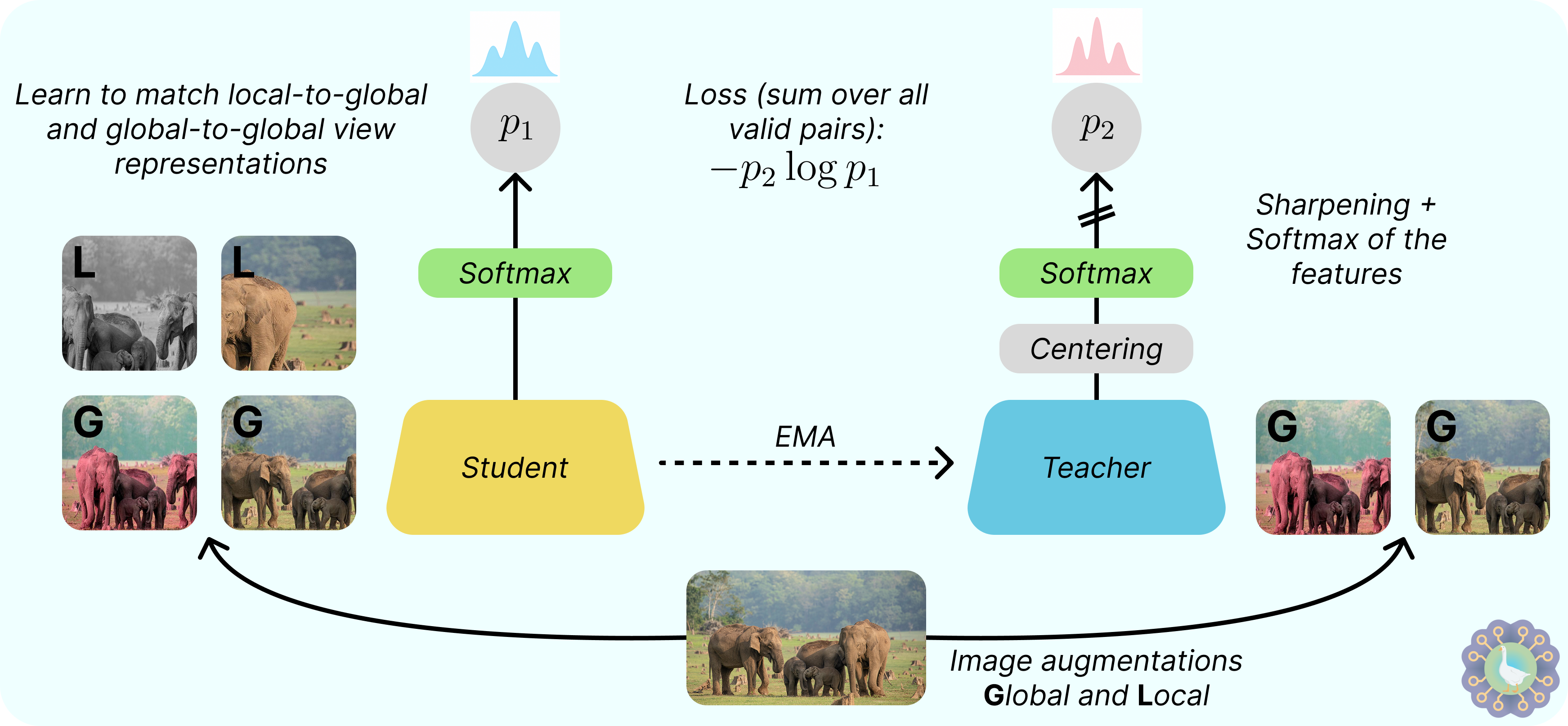
DINO is not contrastive, so it learns by sampling positive image pairs and aligning their representations. However, DINO follows a new multi-crop strategy: first, it generates two large crops (global, covering >50% of the image) and several smaller ones (local, <50%) from the same image. All crops are passed through the student network, but only the two global crops are processed by the teacher, encouraging what the authors call “local-to-global” correspondence. Output matching with cross-entropy happens between all valid pairs of crops, excluding identical view pairs. DINO follows the same set of data augmentations of BYOL, i.e., a mix of horizontal flips, color jittering, grayscale conversion, Gaussian blur, and solarization.
While DINO also works with convnets by matching the state of the art with a ResNet-50 architecture, it is when we plug in a ViT that it truly shines, surpassing other methods by a significant margin. And just like that, SSL and ViTs became best friends, with DINO features being a very popular choice for image retrieval, similarity search, and dense prediction tasks (e.g., segmentation and depth estimation).
Visualizing Feature Maps
One of the most unique properties of Vision Transformers trained with DINO is their ability to implicitly segment objects in an image without ever being taught to do so. This emerges spontaneously as a byproduct of learning to match different local to global views of the same image due to the necessity of learning transferable object patterns that go beyond simple solutions. As humans, we also can infer local to global and assign it a very similar concept in our head.

This extraordinary behavior can be visualized by plotting the attention maps from different heads. Remember, in the attention layers of a transformer, we have vectors corresponding to image patches exchanging information, and we can visualize each patch querying all others in a certain attention head to determine what to focus on. Particularly in the final layer, these heads are specialized and attend to semantically meaningful regions of objects, seemingly getting what belongs together.
These emergent properties reveal a structured understanding of the image that does NOT emerge when training in a supervised manner, likely due to using shortcuts and, therefore, producing less meaningful representations. Attention boundaries often align so well with actual object contours that ViTs pretrained with DINO can, for example, achieve strong video segmentation results, and that is just crazy!
Conclusions
DINO shows that self-supervised learning and Vision Transformers go hand in hand, and when combined, this synergy gives rise to interesting emergent properties without ever seeing a single label [3]. That is exactly what SSL strives for: uncovering rich representations fueled by the scale of modern data!
While DINO features are widely considered a strong candidate for many computer vision tasks, I have personally found through experience that their performance can disappoint a bit when the data distribution differs significantly from natural images, such as in industrial settings. After all, official DINO weights are still trained on the “small” ImageNet, and that is a limitation. That being said, in most cases, there’s little reason not to take advantage of what DINO offers: try it out the next time you have to extract image features for a project.
Hope you enjoyed this breakdown, and see you in the next one!
References
[1] Emerging Properties in Self-Supervised Vision Transformers
[2] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale