
19. BEiT: BERT Pre-Training of Image Transformers
From masked words to masked image patches, nothing changes


Introduction
After the big success of DINO in self‑supervised learning for images, trained to relate local-to-global views and produce highly meaningful and semantically rich features, researchers needed to find a new promising direction. Back to the blackboard, the next advancements came by looking beyond vision toward language models.
Inspired by the masked language modeling approach behind BERT, where parts of a sentence are hidden and the model learns by filling in the blanks, Microsoft brought this concept to the visual domain and developed BEiT [1] (BERT Pre-Training of Image Transformers), a model that predicts the representations of missing image patches using surrounding context.
Although this idea still relies on an external tokenizer, it showed that it was possible to shift the paradigm from contrastive and teacher-student frameworks to a simpler, more unified learning approach. Let’s dive in!
The masked modeling strategy
Before diving deeper into BEiT, it’s worth revisiting the Masked Language Modeling objective used to train BERT [2], which works as follows:
Input sentences are tokenized into a sequence of discrete word tokens.
A portion of the tokens (typically around 15%) is randomly selected and replaced with a special [MASK] token.
The transformer encoder processes the full sequence and learns to predict the original tokens at masked positions using the surrounding context. It does so by minimizing the cross-entropy loss between its predictions and the actual masked tokens.
In addition to this, BERT also uses a Next Sentence Prediction (NSP) objective. This auxiliary task helps the model understand sentence-level relationships by training it to predict whether one sentence logically follows another within a pair. Cool idea, but not really something you can transfer over to single images.
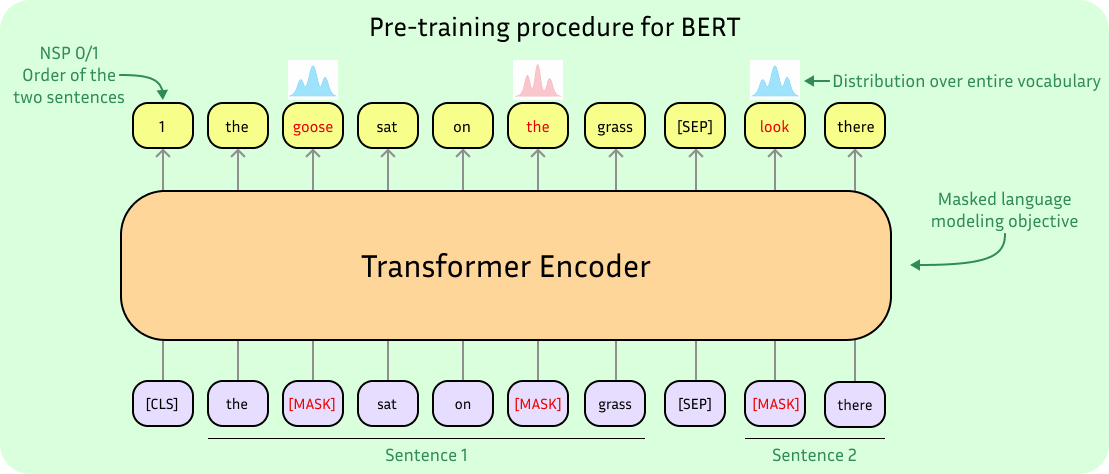
A key distinction between GPT, which is used for text generation, and BERT, which serves as a sentence encoder, is that the latter employs bidirectional attention. This means it can attend to both preceding and succeeding tokens, as the entire sequence is also available at inference time. As simple as it is, this mechanism allows BERT to develop a deep and contextualized representation of language.
Importantly, the prediction targets are discrete symbols (token indices from the vocabulary), not raw text or characters. A direct translation of this idea into vision would mean designing a system where the model predicts discrete visual tokens rather than raw pixel values. BEiT does exactly that.
Method
BEiT learns by hiding parts of an image and training a transformer model to recover the missing content. Anticipating a more recent trend in self-supervised learning, the model actually predicts a representation of the masked regions rather than directly reconstructing pixels. It does so using a “two views” strategy:
First view: the input image is processed by a pre-trained discrete Variational Autoencoder (dVAE), which maps the image into a 14×14 grid of visual tokens drawn from a learned vocabulary of size 8192. Sounds familiar? Yep, it’s exactly what we saw last week! BEiT reuses the publicly available image tokenizer from DALL-E to generate these discrete tokens.
Second view: the same input image is divided into 16×16 pixel patches in the usual way and fed into a standard Vision Transformer (ViT) encoder. Crucially, with this patch size and an input resolution of 224×224, we also end up with a 14×14 grid of image patches. Notice that the number of patches perfectly matches the number of visual tokens from the dVAE, and this is totally wanted to ensure the two views are spatially aligned.
At this point, we have two representations of the same image: one comes from simply splitting the image into patches and passing them through the ViT encoder, while the other comes from the discrete visual tokens generated by the dVAE. It is across these two views that the training happens.
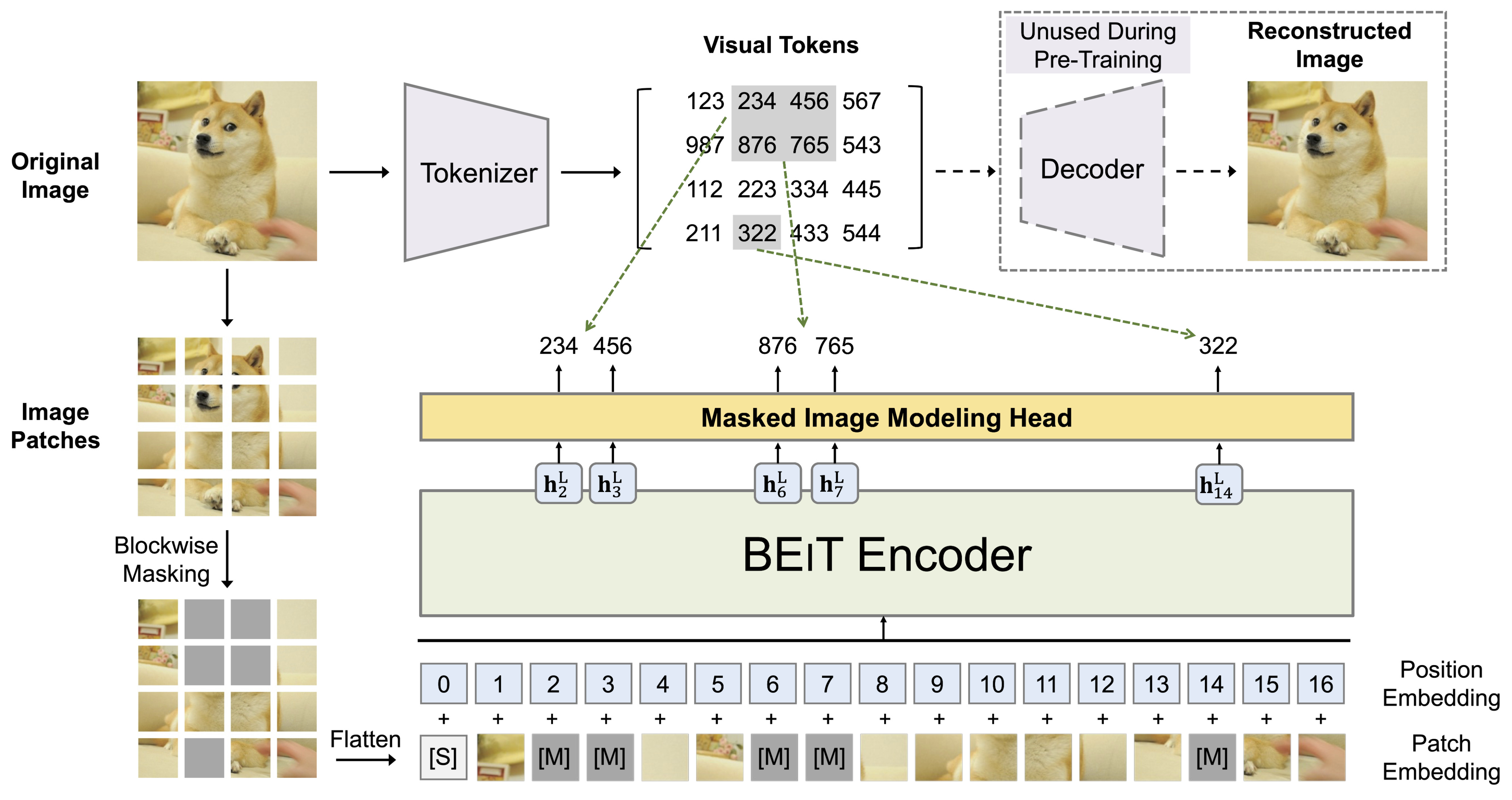
A random subset of pixel patches is masked and replaced with a special [MASK] token, and the model is trained to predict the corresponding visual tokens at those positions using the context. Since the visual dVAE tokens are discrete, the model outputs a distribution for each masked position and now trains exactly like BERT. Notably, BeiT requires no architectural modifications to ViT, so the resulting encoder can be directly used for downstream tasks!
Masking strategy
Unlike in language, random masking doesn’t work well for images due to their strong local correlation. Therefore, rather than randomly choosing patches for the masked positions, BEiT uses blockwise masking. This means larger contiguous portions of the image are masked, following a simple algorithm on blocks of patches:
A block is constrained to cover at least 16 patches and a maximum of 75 patches.
For each masking block, the aspect ratio of the sides is randomly chosen, resulting in a variety of rectangular shapes.
Patches within the block are then masked, and all steps are repeated until 40% of the total image patches have been masked.
This method increases the difficulty of the reconstruction task and encourages the model to learn more global and semantic features that represent what could be behind those large masked blocks, rather than high-frequency details. The augmentation policy in training includes just random resized cropping, horizontal flipping, and color jittering. Despite its simplicity, this is enough to outperform DINO when fine-tuned on downstream supervised classification and segmentation tasks.
Conclusions
BEiT showed a creative transfer of ideas from language to vision, highlighting once again the versatility of the transformer architecture. But despite its strengths, the reliance on a high-quality discrete tokenizer introduces an external dependency that can bottleneck performance when scaling data and models.
Moreover, concurrent work began to reveal that direct pixel-level reconstruction, if carefully managed, can be just as effective. This opens the door to even simpler, end-to-end pretraining strategies without the need for external components. Guess that will be the bread for the next chapter in our pre-training series. See you next week!
References
[1] BEiT: BERT Pre-Training of Image Transformers
[2] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding