


22. Zero-1-to-3: Zero-shot One Image to 3D Object
Turn Stable Diffusion into a multi-view synthesis engine!

Introduction
Creating a 3D model from just a single image is a fundamentally ill-posed problem, since one view alone doesn't provide enough information to do the job. However, we as humans can do this remarkably well in our minds, thanks to extensive exposure to everyday objects and acquiring data from lots of angles. This suggests that a strong image prior might be the key to producing a plausible solution to monocular 3D reconstruction.
Today, we dive into “Zero-1-to-3: Zero-shot One Image to 3D Object” [1], where the authors leverage the vast image knowledge embedded within modern diffusion models like Stable Diffusion and turn it into a powerful tool for novel-view synthesis and ultimately reconstructing 3D objects from a single image.
Background context
At this point, it should come as no surprise that models (pre)trained with massive internet-scale datasets exhibit powerful emergent properties. If we take Stable Diffusion (SD), trained on billions of images, it turns out that the model implicitly learns depth and volumetric semantic priors despite having only ever seen 2D data. This means it has the notion of near-far, object boundaries, occlusions, and so on.
On top of that, as a generative model, SD can generalize beyond training data right out of the box, accurately synthesize (to some extent) diverse viewpoints of similar objects, and create high-quality visual details and textures. This sounds like exactly what we need, if only we could control it precisely…
The problem is that the representations do not explicitly encode correspondences between multiple viewpoints, and keeping the same object identity across different generations is generally hard. Also, the model inherits several biases from internet images and might struggle to generate certain poses (e.g., the back of a chair). But this is nothing some fine-tuning cannot fix, and it is exactly the strategy of Zero-1-to-3.

Method overview
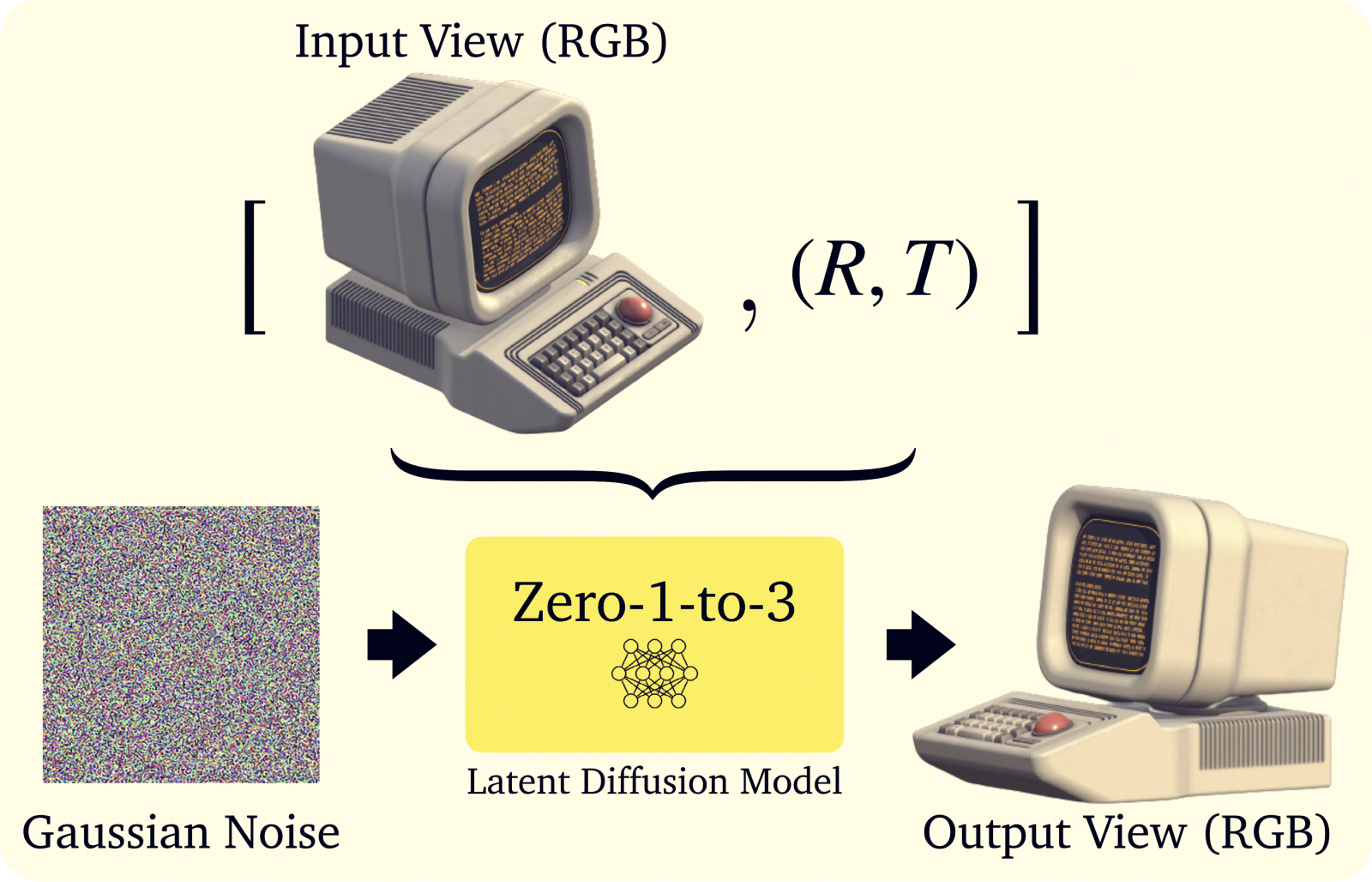
Given a single RGB image x of an object, the goal is to synthesize a new image of the same object from a different camera viewpoint. Let R and T denote the relative camera rotation and translation that define the desired viewpoint, respectively. We want our generated view f(x, R, T) to be perceptually similar to the input x and respect the camera constraint as well.
Standard SD takes a text prompt as input and generates an image that reflects the described scene. However, this is not enough to solve the novel view synthesis and 3D reconstruction tasks, even if fine-tuned with detailed descriptions of the object and camera position. To succeed, the architecture must be modified in two ways:
Embed the original input view directly into the diffusion process, providing a precise visual reference to guide generation and maintain object consistency.
Quantitatively condition the model on the novel camera position using explicit extrinsics.
This is achieved through a hybrid conditioning mechanism, with only minimal changes to the original model design:
On one side, a CLIP [2] embedding of the input image is concatenated with the camera position (R, T) to form a “posed CLIP” embedding c(x, R, T) and fed to the denoising U-Net via cross-attention. This encodes the high-level semantics of the input image and swaps the standard text embedding conditioning of SD.
On the other hand, the input image is encoded into latent space and concatenated channel-wise with the noisy image being denoised at each U-Net step. This encodes the object identity and fine details of the item being synthesized, with the idea that an image is worth a thousand words when trying to copy identity.
And that is it from the architectural side! With these two forms of conditioning, the model has access to both geometry and identity. Note that the VAE is not mentioned because it is not changed. While the denoising model needs to be repurposed for a new task, the image encoding and decoding into latent space already work well with images from all angles.

Training and inference
While 3D asset datasets are not as large as image datasets, Zero-1-to-3 does not train from scratch and can therefore make effective use of the “small” Objaverse dataset (800K+ 3D models created by 100K+ artists) to transfer SD from text-to-image generation to image-plus-camera-to-image synthesis.
For each object in the dataset, 12 camera extrinsic matrices pointing at the center of the object are randomly sampled, and 12 views are rendered with Blender, a raytracing engine. At each training iteration, two of these views are taken to form an image pair, and the corresponding relative camera transformation (R, T) defining the mapping between the two perspectives is computed.

At this point, the target view is encoded into latent space using the VAE, and noise corresponding to a specific timestep is added, following the standard diffusion process. Meanwhile, the reference view is also encoded with the VAE to obtain its clean latent image tensor. This reference latent is then concatenated with the noisy target latent and fed into the U-Net, which has double the number of input channels to accommodate for this.
Only the U-Net is then trained to denoise the target latent, just as in a standard diffusion model (you can always refresh how SD works in post #16). Crucially, all this fine-tuning happens with ray-traced synthetic data (which offers the best quality), and generalization to real objects is left to the power of the pretrained prior.
At inference time, all we need is a picture of an object and a new camera position (if particularly lazy, also a text description works, since we can generate images from text using DALLE or the original SD). After encoding the input image into latent space, we start from a random target view tensor and we run the U-Net denoising process for multiple steps following the full diffusion schedule. Finally, we decode the clean latent and get the novel view out.
To take it a step further and generate a full 3D model, multiple viewpoints are synthesized from different camera poses and then fed into standard multi-view reconstruction algorithms.
Conclusions
Zero-1-to-3 is one example of exploiting the immense potential of geometric priors hidden in generative models. Still, doing such a “big” task transfer requires fine-tuning the model on an 8×A100 machine for 7 days, which is far from accessible.
What is truly impressive is the robust zero-shot capability on objects in the wild, including artistic styles, internet-sourced images, and complex geometries never encountered during training. Even more remarkable is the speed: this diffusion-based approach can synthesize novel views in just a few seconds!

Given how difficult and inherently underconstrained the task is, some uncertainty in unobserved regions is to be expected. Still, this method makes 3D content creation more intuitive and accessible, and considering the progress made in image generation in the past year, exciting times are ahead! If you like, you can try Zero-1-to-3 out on Hugging Face at [3]. See you next week.
References
[1] Zero-1-to-3: Zero-shot One Image to 3D Object
[2] Learning Transferable Visual Models From Natural Language Supervision
[3] HF Demo: https://huggingface.co/spaces/cvlab/zero123