
30. IP-Adapter
Enable image prompt capabilities for pre-trained text-to-image diffusion models


Introduction
Welcome back to our monthly series on personalizing Stable Diffusion: we’re almost at the finish line! Last time, we covered DreamBooth, the go-to method for high-fidelity subject-driven generation. This week, we are diving into Image Prompt Adapter by Tencent AI Lab [1], a lightweight module designed to condition image generation on both visual and textual inputs, enabling de facto multimodal guidance.
Similar to Textual Inversion, IP-Adapter requires no fine-tuning of the base model and trains only the necessary set of parameters to allow passing an image as input. Let’s unpack how this works and what purposes it serves!
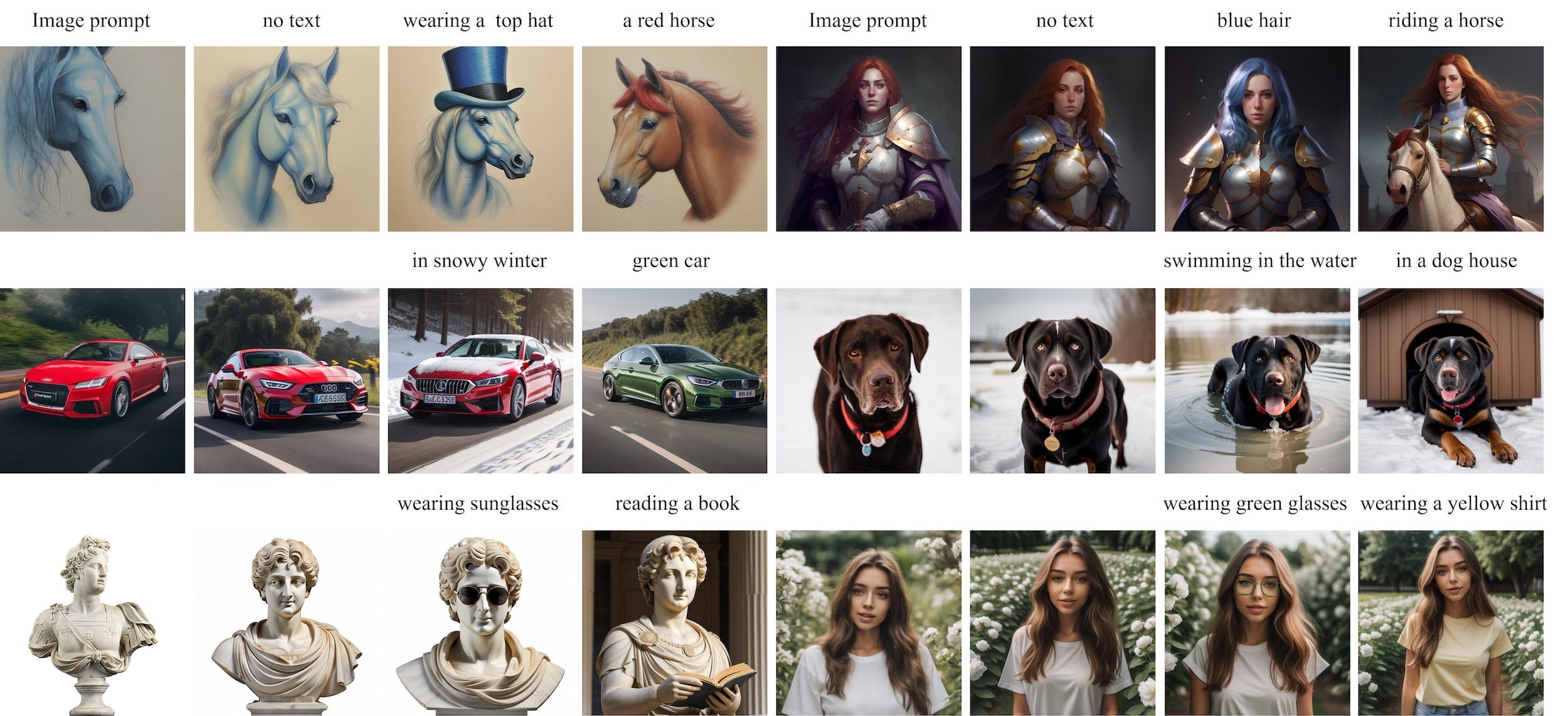
The cross-attention mechanism
Let’s take a quick moment to recap how cross-attention works, as it plays a central role in how IP-Adapters operate. In Stable Diffusion and other transformer-based generative models, cross-attention is the mechanism that connects the conditioning input, typically the text prompt, to the visual generation process.
More broadly, cross-attention allows two different sequences of tokens to interact. This serves a complementary purpose to the more well-known self-attention, which enables information exchange only between tokens within the same sequence, and guarantees spatial coherence in the case of SD.
Now, the denoising U-Net in SD includes several blocks of both. In self-attention, each image token generates its query Q, key K, and value V via learned projection matrices. In cross-attention, tokens from the first sequence generate the queries, while the second one provides keys and values. In both cases, the standard attention formula applies [2], and it’s just a matter of where we get the Q, K, V inputs from!
So, when it comes down to the cross-attention in text-conditioned image generation:
Q comes from the visual features (image latents).
K and V come from the conditioning input (text embeddings).
Method
As the saying goes, “an image is worth a thousand words”. Even so, IP-Adapter isn’t meant to replace text conditioning with image conditioning. Instead, it offers the option to do so when needed, and in most cases, it’s designed to complement text and enable both modalities to condition together.
The idea behind it is to extend the cross-attention mechanism by adding a new set of weights to inject visual features extracted from an input image and summing up with the contributions from the standard text branch.
We start with an image we want to condition on, typically to replicate the background, style, or subject. Then, we use a pre-trained CLIP image encoder to extract features from it. These representations are naturally well-aligned with text embeddings due to the multimodal pretraining, making them ideal for quick integration into the model.
The global image embedding then goes through a small trainable projection network, transforming it into a sequence of features of length four and dimension equal to the text features in the pretrained diffusion model. Long story short, the image prompt now is represented exactly in the same way as a text prompt would!
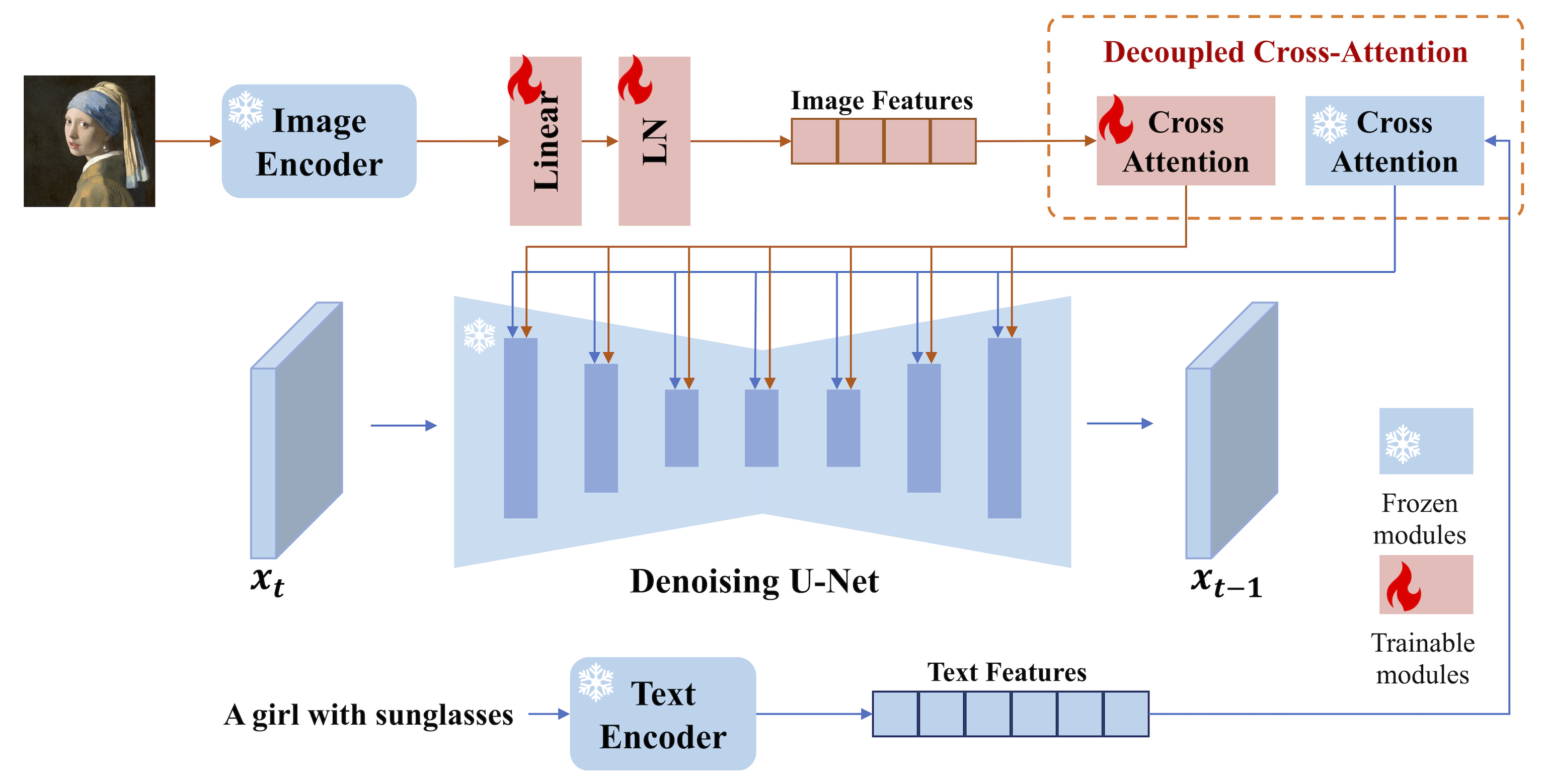
Instead of concatenating text and image tokens, a method found to be insufficiently effective, we duplicate the conditioning mechanism. A decoupled design is used, where the text and image features are handled by separate cross-attention layers and their outputs summed. So, for each cross-attention layer in the UNet, we:
Add a new, separate image-to-image attention contribution to insert image features into the denoising model.
Initialize its K’ and V’ projection matrices from the corresponding text projection matrices, in order to speed up convergence. Note that Q is shared between the image-to-image attention and the image-to-text one, so we only need to add those two matrices for each cross-attention layer.
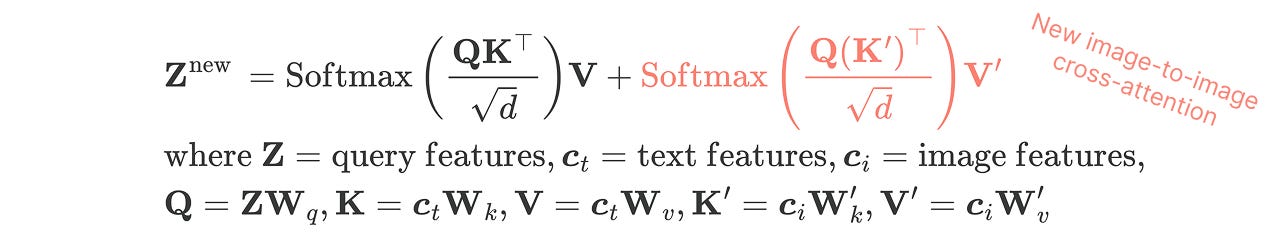
Training
All that is needed now is a bit of training! Everything is kept frozen apart from the projector and matrix pairs at each cross-attention layer, making the system super lightweight (22M parameters for SD version 1.5).
The training set is a bit surprising: one would think that to do (image+text)-to-image, you would need a set of triplets of input image, text prompt, and target image. Reality is that the model never sees the conditioning image directly. It just sees its CLIP embedding (a lossy representation!), so it is sufficient to train on standard image-text pairs, treating the image both as target and additional conditioning.
Thus, IP-Adapter is trained on about 10 million text-image pairs from two open-source datasets. To enable using just the image conditioning, the text is dropped with a small probability by simply zeroing out its embeddings. Almost like magic, scaling up the data lets the model do more than just “reconstruct” the conditioning image!
Inference
At inference time, we simply compute attention over the available conditioning signals and sum their respective contributions. Since we train with random dropping of the conditions and the text cross-attention and image cross-attention are detached, we can prompt with both, just an image, or perfectly retain the original text-only model capabilities, depending on the need.
And it doesn’t stop here! Since this mechanism is fully baked into the architecture, we can also seamlessly plug IP-Adapter models into more complex pipelines using ControlNet [3], enabling flexible combinations of image prompts, text prompts, and even structural controls!
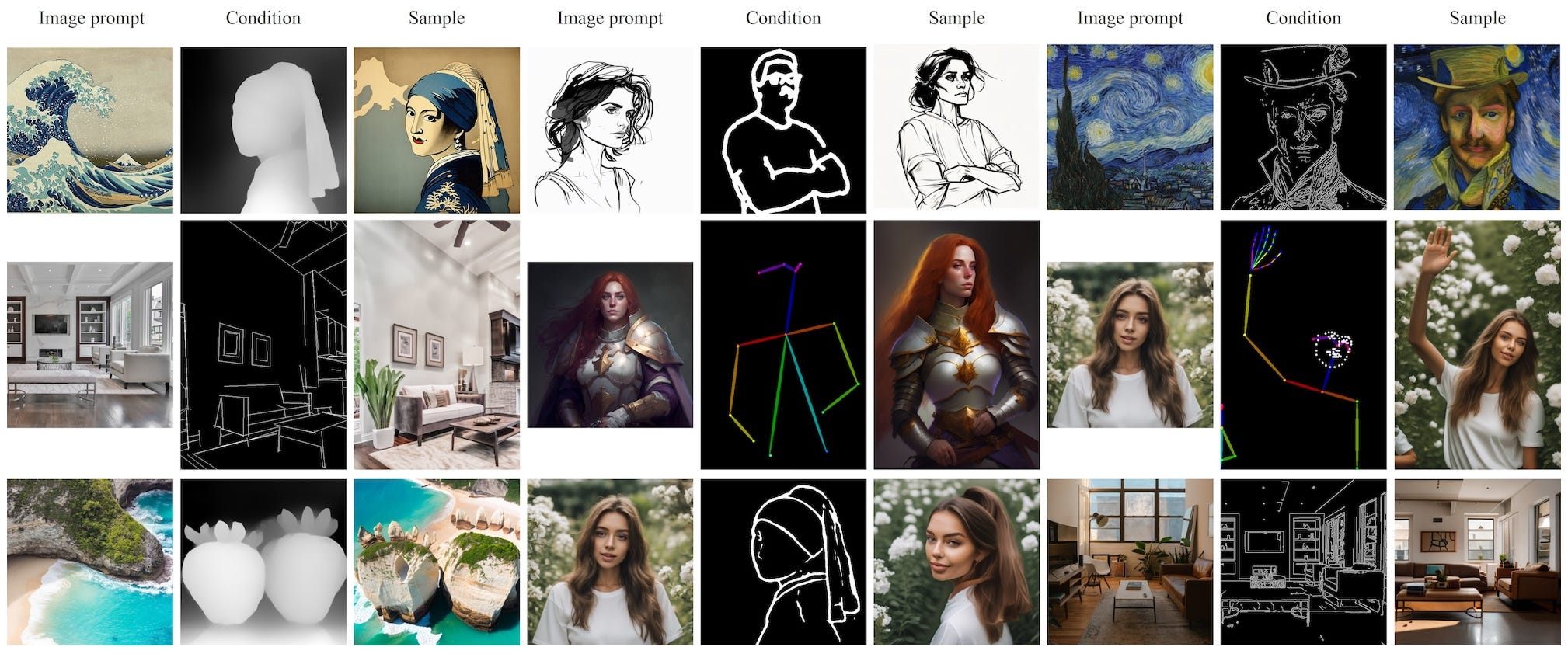
Conclusions
IP-Adapter brings a new dimension to Stable Diffusion personalization with image-based guidance without retraining the base model. Unlike DreamBooth, where each subject requires a new fine-tuned model, IP-Adapters are trained once by the big AI labs on large-scale image-text pairs and work in general to inject subject or style cues. Once the IP-Adapter is trained, it can be directly reused on custom models fine-tuned from the same base model!
In summary, IP-Adapter relies on a decoupled cross-attention and allows for multi-modal prompting, embracing the fact that detailed textual descriptions are good and complementary, but “an image is worth a thousand words”.
To wrap up this exciting month, next time we’ll dive into Marigold, turning diffusion-based image generators into discriminative models capable of predicting depth maps, surface normals, and many other dense modalities. This is particularly close to my heart, as I had the opportunity to work on extending it for my master’s thesis and understand the potential hidden in this class of models. See you next week!
References
[1] IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
[3] Adding Conditional Control to Text-to-Image Diffusion Models