
31. Marigold
Repurposing diffusion-based image generators for dense prediction tasks


Introduction
Welcome back to our monthly series on personalizing Stable Diffusion: this is the final episode! Over the past four weeks, we’ve looked at how to provide additional image conditioning (IP-Adapter), generate high-quality images of a subject (Textual Inversion, DreamBooth), and adapt models to specific styles or characters using the same type of lightweight fine-tuning (LoRA) that can be used for LLMs.
Today, we’re turning things upside down and using Stable Diffusion not to generate images, but to understand them. Enter Marigold [1, 2], a method that repurposes diffusion-based image generators for dense prediction tasks such as monocular depth estimation, surface normal prediction, and intrinsic image decomposition. All this can be achieved on a consumer GPU within a couple of days!
For the sake of explanation, this post focuses on the original Marigold release [1] for monocular depth estimation, i.e., determining how far each pixel is from the camera. But all the same ideas transfer with no change to many other dense regression tasks, as detailed in a recent extension [2] and shown below. More on that later!

Image generation as a world model
You might be wondering: how is this even possible? How can a model trained to generate pretty pictures also be good at estimating depth? Well, the answer lies in both the amount of data it is exposed to and the nature of the generation task itself.
First off, training a model on billions of images for any non-trivial task inevitably leads to the emergence of useful internal representations. SD is no different: trained on a subset of LAION-5B and exposed to virtually everything imaginable, it developed robust, general-purpose priors about how natural images are structured. In short, it learned to model the world.
Secondly, high-resolution image generation is very hard! To generate coherent images from just text and noise, diffusion models need to grasp, among other things:
3D geometry. How objects are shaped, positioned, and related in space.
Semantics. Knowing what things are and what they look like, including their form and volume, to some extent.
Perspective. How the 3D world projects onto the 2D image plane.
That means they are rich repositories of visual cues. Does predicting depth still look odd now? That is the entire premise of Marigold: if the model already knows so much about images, then funneling these aspects should be very easy!
One VAE to encode them all
Stable Diffusion is a latent diffusion model, meaning it operates in the compressed latent space of a variational autoencoder (VAE), rather than in pixel space. Although ignored for the past four weeks, it plays a crucial role in Marigold, as it is used not only to encode images but also to handle new output modalities like depth.
Once again, this flexibility comes from the scale of the dataset: in a collection as large as LAION-5B, a meaningful subset consists of grayscale or low-saturation images. Hence, the VAE also learns to compress and decompress images with basically a single channel (even though they might be presented as RGB).
During VAE training, images are normalized to [-1, 1] before being fed into the model. If we take a depth map in [a, b] and apply min-max or quantile normalization plus some shifting, it also lands in the familiar range [-1, 1]. While we lose absolute scale (depth becomes affine-invariant), we gain compatibility with the model’s input range!
If we then replicate the depth map into three channels, we simulate an RGB image. And here is the good part: if we encode and then decode this with the VAE and average the channels back, the reconstruction error (as the VAE is a tiny bit lossy) on the depth map is comparable to that of a real RGB image!
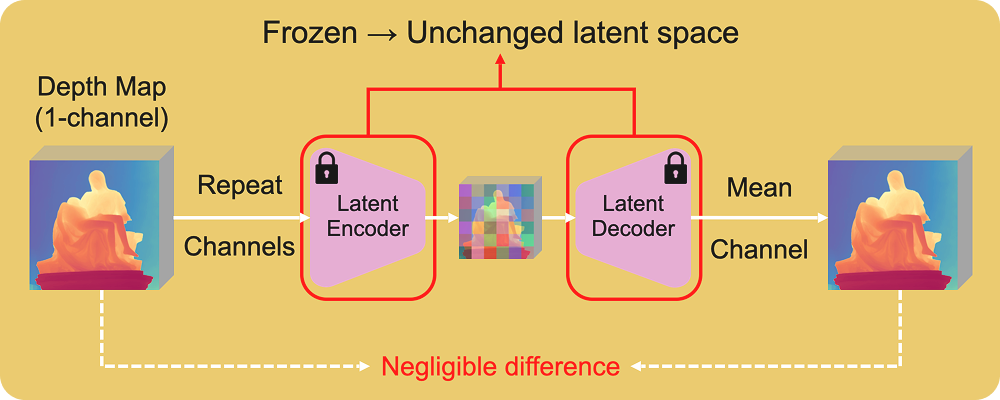
This means the latent space of the VAE is flexible enough to generalize to other dense modalities normalized to [-1, 1], provided that they resemble grayscale images in distribution. This also means any repurposing of the model for those modalities (e.g., from text-to-image to image-to-depth) can leave the VAE untouched and frozen!
The Marigold fine-tuning protocol
The original SD takes text as input to generate an RGB image. In contrast, Marigold takes an image as input and produces a corresponding depth map. To enable this, two key modifications are made: first, the model is conditioned on an RGB image instead of a text embedding; second, it is trained to predict a latent depth map.
As we’ve discussed, this depth map can be represented as a three-channel image, allowing us to train the diffusion model using the original SD setup. This means the clean depth map is encoded into latent space, noise is added, and the denoising UNet is tasked with reconstructing the original clean depth latent from the noisy input.
As for the image conditioning, we saw last week how IP-Adapter does it. However, in this case, we want the depth map to be sharp and pixel-aligned with the input image. This requires a different strategy: instead of extracting features, we encode the RGB image directly into latent space with the VAE and pass it as an additional input to the denoising UNet, ensuring tight spatial correspondence between input and output.
The UNet is modified by doubling the input channels to accommodate this additional input and dividing the values of the first weight tensor by two to prevent the inflation of the activation magnitudes. As for the original text conditioning, we invalidate it by always passing an empty string. That’s it!
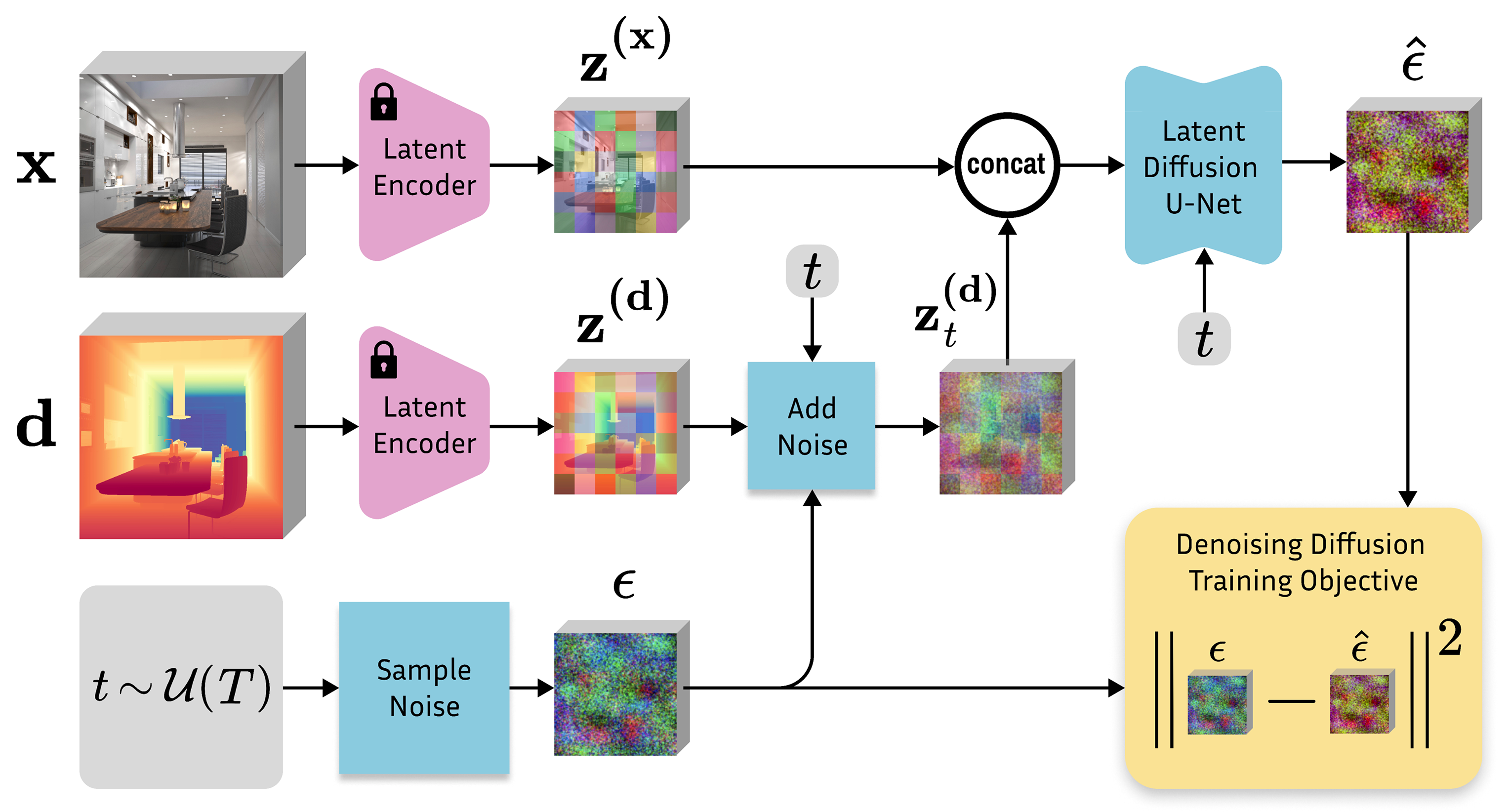
To train the denoising model, we don’t start from scratch but instead retain all the image denoising knowledge by initializing from the original image weights. What follows is a lightweight fine-tuning that takes approximately 2 days on a single consumer GPU. So, the new training process looks like this:
Pick an image, its depth map, and a timestep. Marigold uses a standard diffusion schedule in training, with 1000 noise levels.
Encode the image conditioning. The RGB image, for which we want to predict the corresponding depth, is sent into latent space with the VAE encoder.
Encode the depth output. The corresponding depth map, normalized to the range [-1, 1], is repeated to simulate an RGB image and encoded using the VAE as well.
Add noise. Gaussian noise is added to the target depth latent according to the schedule, and the noisy depth latent is passed as input to the modified UNet along with the (clean) latent RGB and the empty text string.
Compute loss and update the UNet. The model minimizes the difference between the predicted noise and the actual noise added to the depth latent, using a standard noise prediction loss such as mean squared error.
With the VAE frozen, repurposing only the latent diffusion model to the new task of image-conditioned depth denoising requires a compute budget that is ridiculously small compared to the original SD budget. On the other side, it is exactly this short fine-tuning protocol that preserves prior knowledge the most.
Synthetic data all the way
As for the datasets, Marigold relies on 74K synthetic depth samples only. This is especially outstanding compared to competitor models trained on millions of images. This has mainly two motivations:
First, synthetic depth is dense and complete, meaning that every pixel has a valid ground truth depth value. This is needed to feed such data into the VAE, which cannot handle data with invalid pixels.
Second, synthetic depth is the cleanest possible form of depth, guaranteed by the rendering pipeline.

This approach was later picked up by subsequent works, which confirmed Marigold’s findings about the effectiveness of training only on synthetic data and excluded real data from their pipelines. Something to reflect on!
Strengths
If turning a text-conditional image generation model into an image-conditional depth estimator wasn’t exciting enough, here are a few more reasons why Marigold shines:
Zero-shot generalization. Although trained on super small data from just two synthetic datasets (one of indoor scenes and one of outdoor driving), Marigold generalizes incredibly well to real-world, in-the-wild images. This is due to reprogramming the SD visual priors as well as training in affine-invariant settings, where there is only the notion of “near” and “far” instead of metric units.
Minimal architectural changes. By reusing the original VAE, duplicating only the input weight tensor, and focusing mostly on the data pipeline, Marigold fits absolutely into the category of efficient fine-tuning.
High level of detail. Thanks to the generative backbone and training only on clean data, produced outputs are sharp and precise, with a level of detail often absent in standard specialized regression models. This means it can be used for cool stuff like image to 3D printing!
Inference speed. While this high output quality originally came at the cost of speed and was the major criticism, that’s no longer a major limitation. Thanks to the discovery of sub-optimal settings in the diffusion scheduler, Marigold is equally as fast as other models, working with as few as 1-4 steps in inference.
Uncertainty estimation. Since the backbone is generative, by running inference multiple times with different starting noises, we capture a distribution over plausible outputs, estimate the uncertainty, and have a free ensemble of models!
Framework flexibility. While the original paper focused on depth estimation, nothing in the fine-tuning protocol is really tied to it. One can swap a depth map with surface normals, material properties, or potentially even turn Stable Diffusion into a text-grounded segmenter [3], all within a similar scheme.
Conclusions
Marigold is a very elegant example of model repurposing, showing that SD is capable of much more than just generating pretty images and can be turned into a dense predictor by unleashing its powerful and general image prior with just the right data.
The major takeaway is that a small amount of synthetic examples, coupled with an efficient formulation such as operating in latent space, allows fine-tuning and inference on a single consumer GPU. Empowering research even outside large labs was certainly one reason why it was competing for the Best Paper Award at CVPR ‘24.
With this, we wrap up the month of SD personalization: I hope you enjoyed it! Check out all Marigold resources at https://huggingface.co/prs-eth and see you next week, back to variety!
References
[1] Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
[2] Marigold: Affordable Adaptation of Diffusion-Based Image Generators for Image Analysis
[3] Cocogold: training Marigold for text-grounded segmentation