
48. Video Models are Zero-shot Learners and Reasoners
The GPT-3 moment for computer vision?


Introduction
We are likely all familiar with the “eureka” moment that happened in natural language processing a few years ago. Following the release of GPT-3, we realized that training a massive language model on enough internet text transforms it from a simple text predictor into a general-purpose reasoner [2]. In particular, the same model can be asked to translate, summarize, write code, and perform many other tasks.
With it, the notions of prompting and in-context learning were born. This means we do not need to update the model weights for every new task; instead, we simply provide clear instructions or examples in the prompt, and the model adapts on the fly. It just works, zero-shot.
It is fair to say that computer vision has lagged behind this paradigm. We still build specialized models for classification, segmentation, depth estimation, object tracking; you name it. A promising direction has come from VLMs (honorable mention goes to PaliGemma 2 mix [3]), but what if video generators are the ones having their own “GPT-3 moment”?
Today, we look at a paper from Google DeepMind that claims exactly this [1]. They show that Veo 3, their latest video generation model, can solve complex vision tasks it was never explicitly trained for. Lots of cool stuff coming!

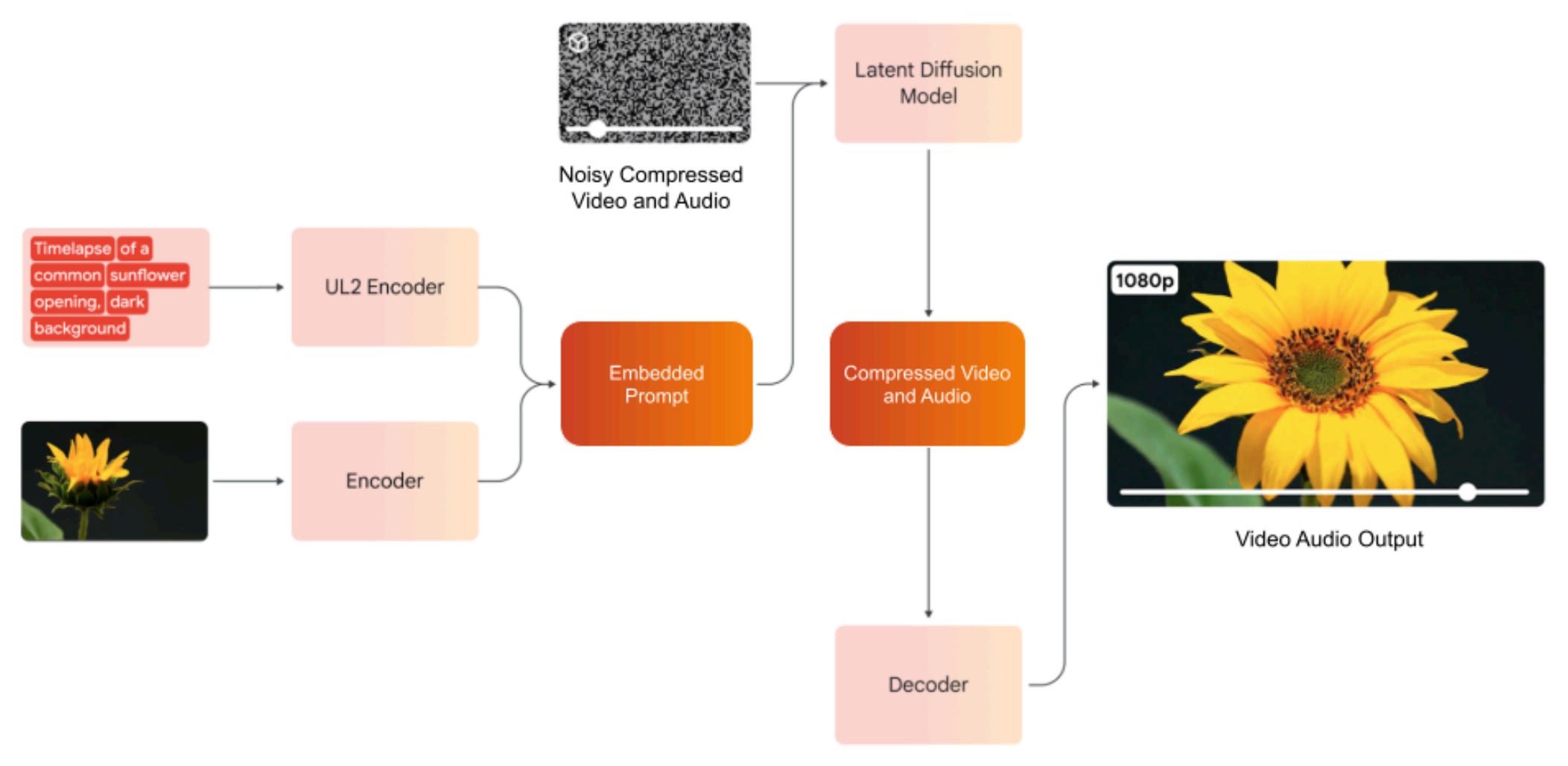
Veo 3 architecture
If you have ever been fooled by a semi-realistic AI video on social media, you have likely seen the power of Veo 3 firsthand. Veo is a large-scale generative model capable of synthesizing high-quality videos with audio from a text prompt or input image.
While the exact details of the model are not known yet, we learn from the tech report that the system uses a transformer-based latent diffusion architecture [4]. If this rings a bell, it’s because we covered this last week! This design is similar to state-of-the-art image generators, and it allows the model to learn more efficiently than by using raw pixels and waveforms.
In particular, both video and audio are compressed by respective autoencoders into latent representations. This is where the generation happens, conditioned on regular text and visual prompts. As you can see, the underlying architecture is minimalistic, and the power likely comes from pre-training the model at scale with diverse data, followed by very clever post-training.
Method
The approach of the paper is very straightforward: just ask and watch! Seems a bit like a joke (hey, aren’t LLMs and the way we use them also funny at times?) but the results are truly impressive.
More specifically, the process functions by prompting the model with an image and a detailed text instruction explaining the task, and from there, Veo 3 smoothly reasons through the problem over time and outputs a video that visualizes the solution.

It is easier to show than explain, so here is an example for edge detection. The input is frame 0 with the parrot in regular RGB, and the prompt is “All edges in this image become more salient by transforming into black outlines. Then, all objects fade away, with just the edges remaining on a white background. Static camera perspective, no zoom or pan.”

So as you see, the process is nothing more than a regular use of the model. The generated clip is an 8-second video where the answer to the task is contained within the generated frames (ideally, the last). For example, if you ask for segmentation, the video shows the object slowly separating from the background. If you ask it to solve a maze, the video will show a line being drawn from the start to the finish. And so on.
The researchers call this “Chain-of-Frames” reasoning, drawing a direct parallel to the “Chain-of-Thought” in LLMs [5]. Instead of thinking in intermediate text tokens, the model thinks in intermediate visual frames, solving the problem step by step across space and time. This totally makes sense!

Sparks of visual intelligence
The paper demonstrates success across a wide variety of qualitative and quantitative tasks, categorized into four levels of capability: perception, modeling, manipulation, and reasoning.
To measure performance, Veo 3 is compared against its previous version, Veo 2, as well as the image editing model Nano Banana [6], where applicable. This last one can complete editing tasks with remarkable accuracy, so it is a very strong baseline. The evaluation metric is pass@10, meaning the models are given ten chances to generate a correct result, and the score pass@k is the best score seen so far across k attempts.
Perception
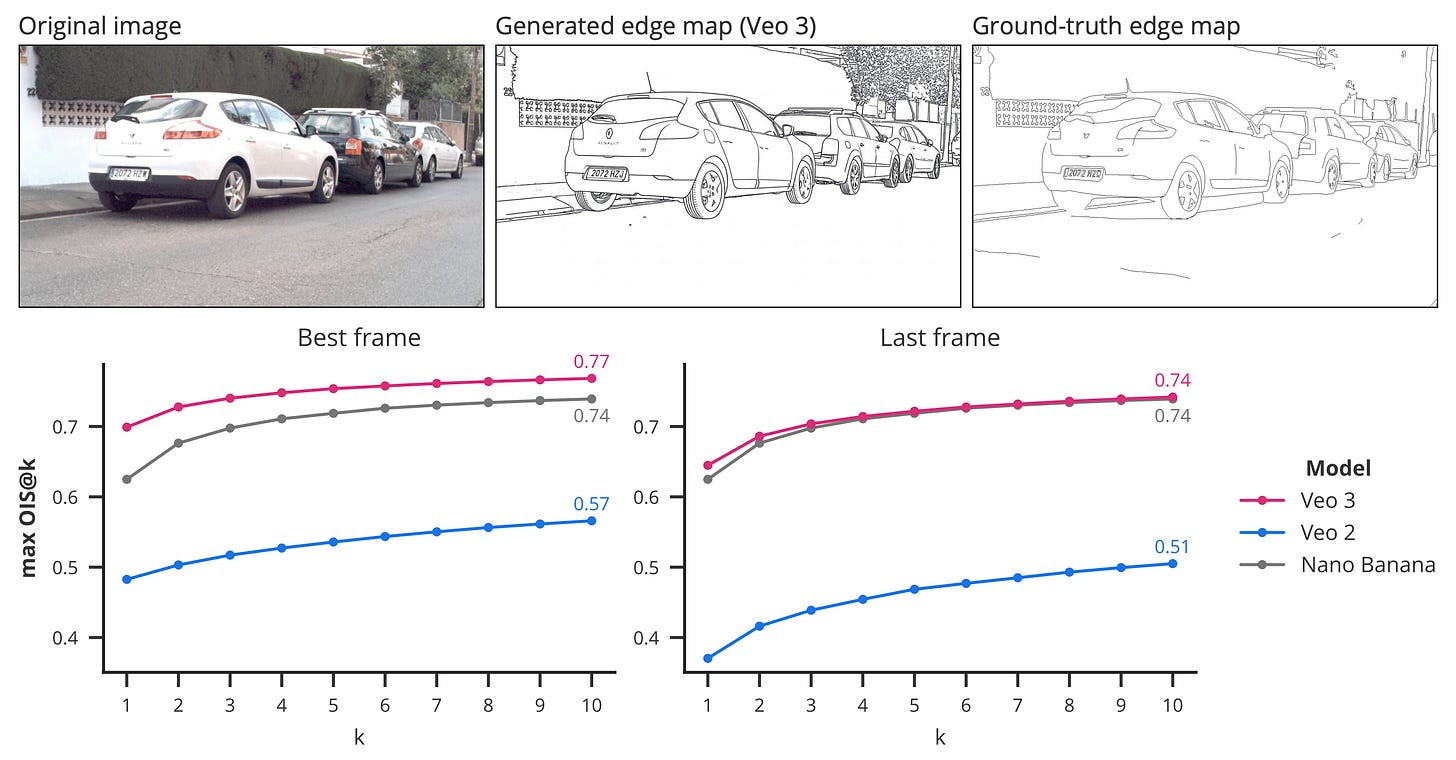
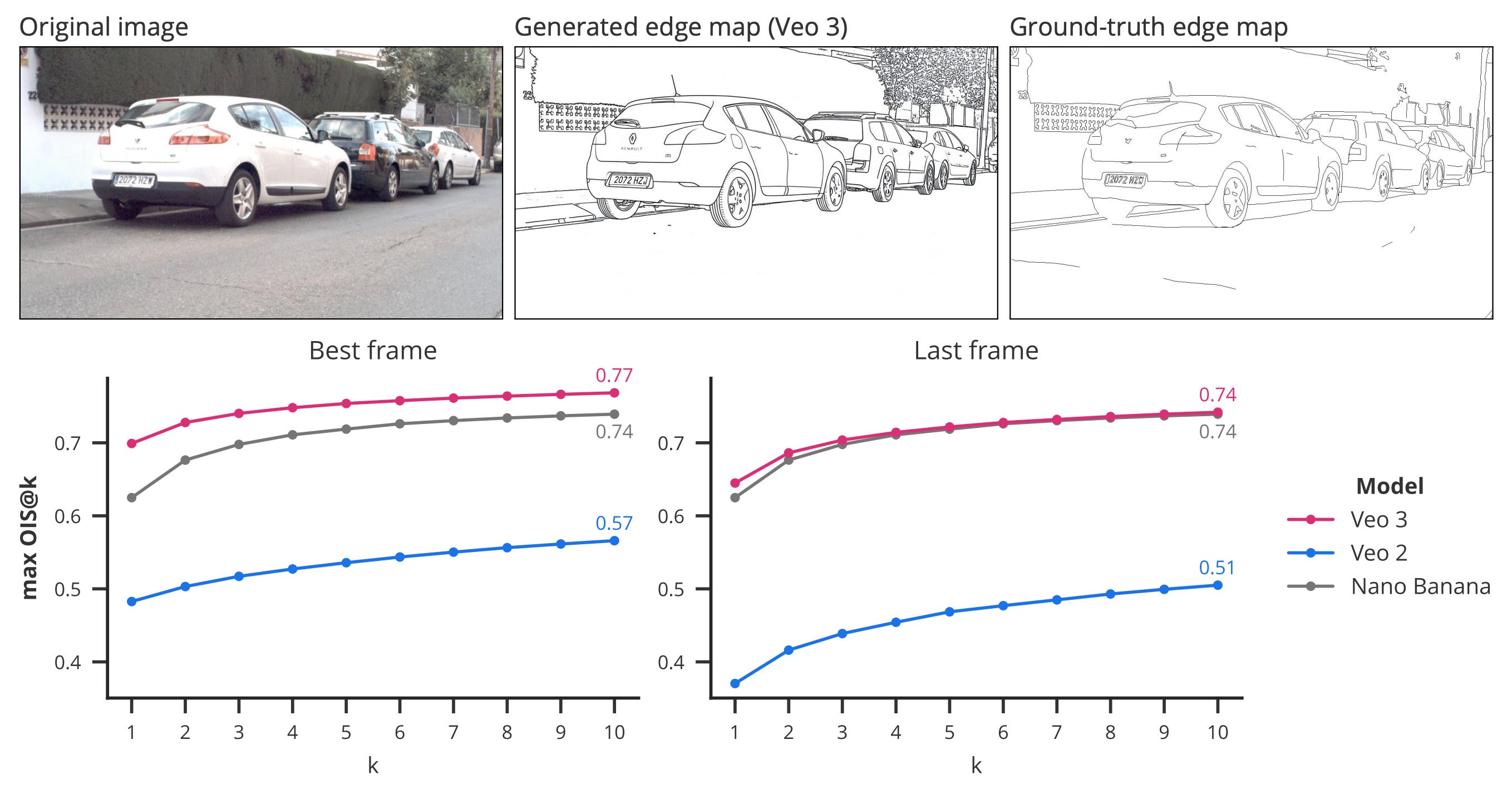
Edge detection. Veo 3 can generate videos where the edges of objects transform into sketches, even correctly handling complex textures like foliage. The results show that these edge maps are even more detailed than the ground truth data!
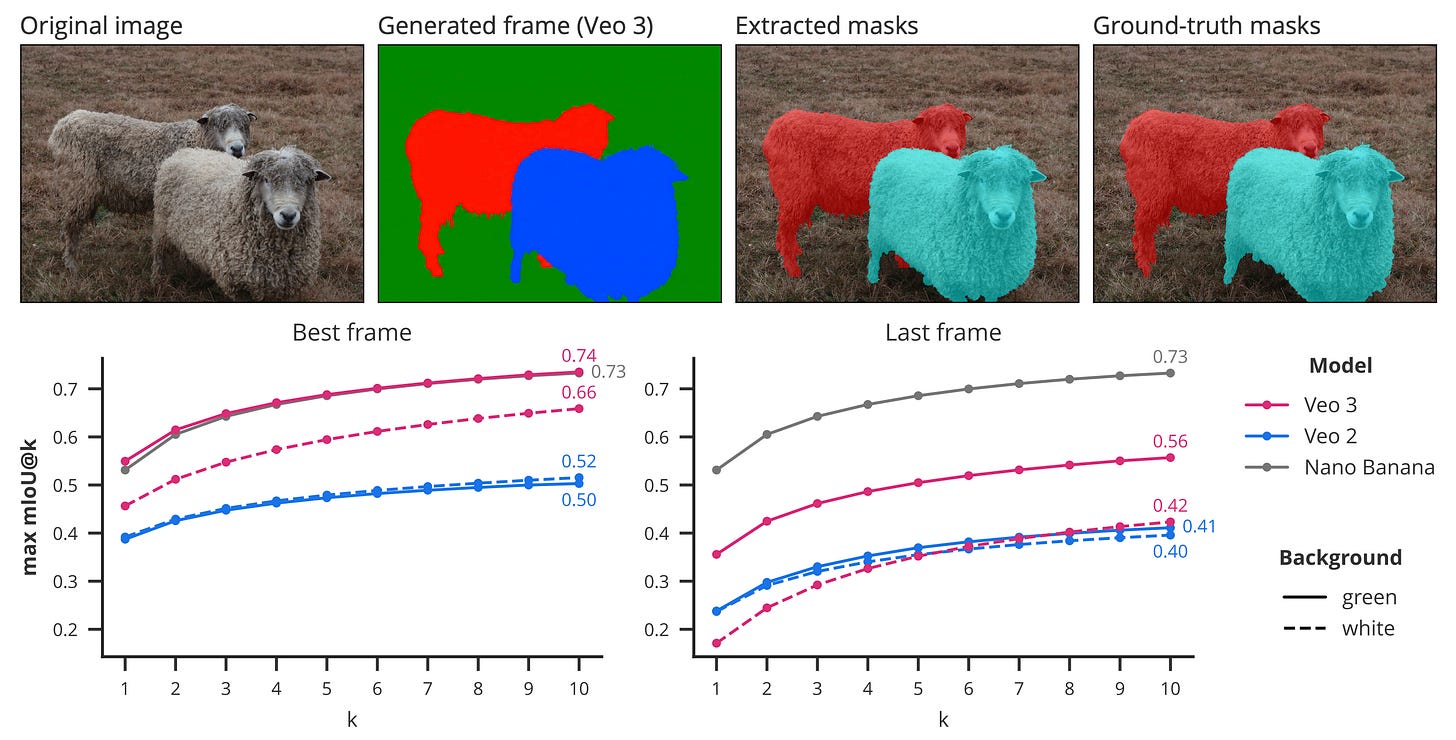
Segmentation. It can separate all objects from their background, without specifying an object category or location. Naturally, Veo 3 performs worse compared to specialized models like SAM, but still shows remarkable zero-shot segmentation abilities. Fun fact: it performs significantly better when asked to return results on a green background rather than a white one, possibly due to the widespread use of green screen videos in training.
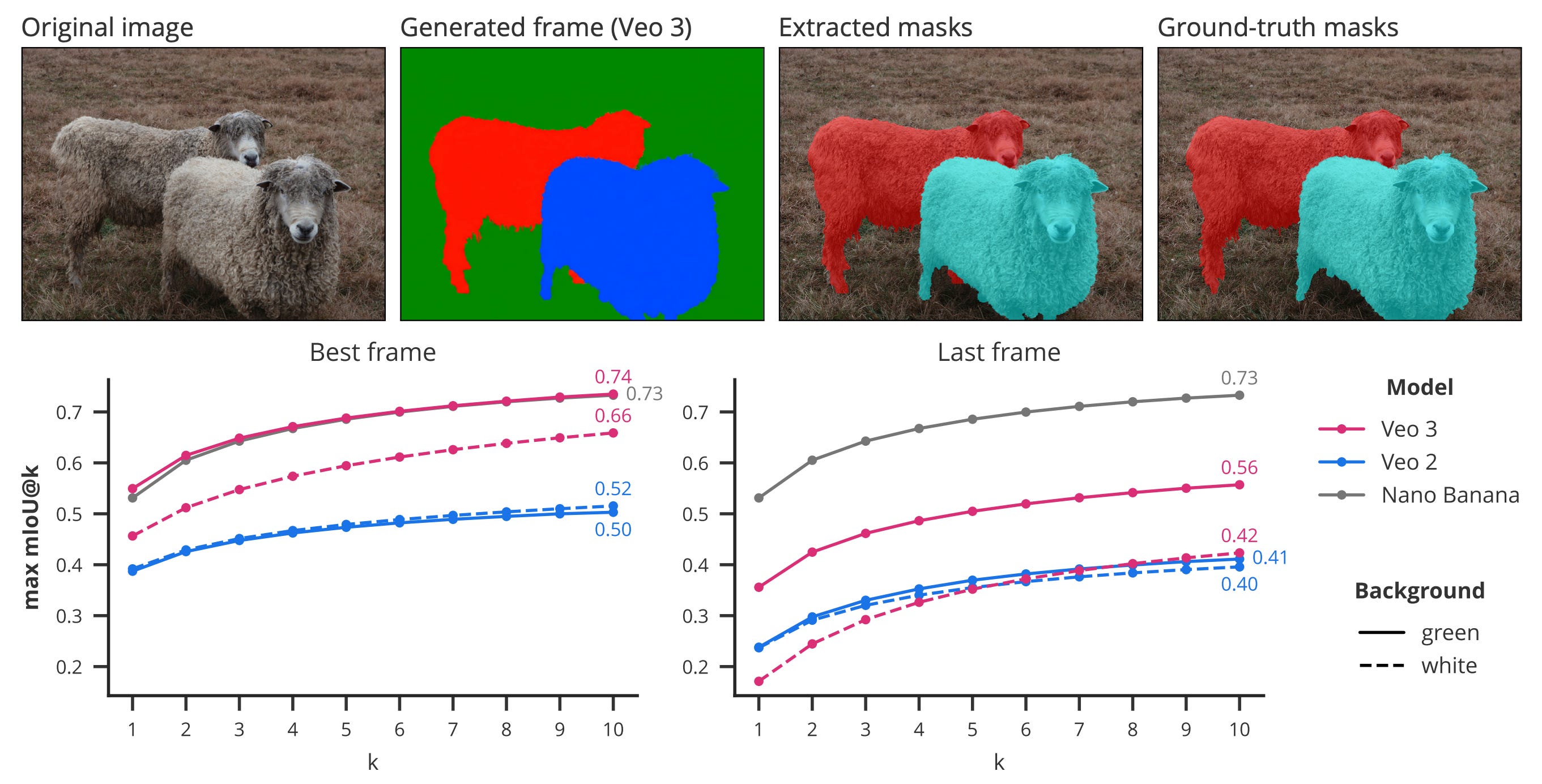
Manipulation
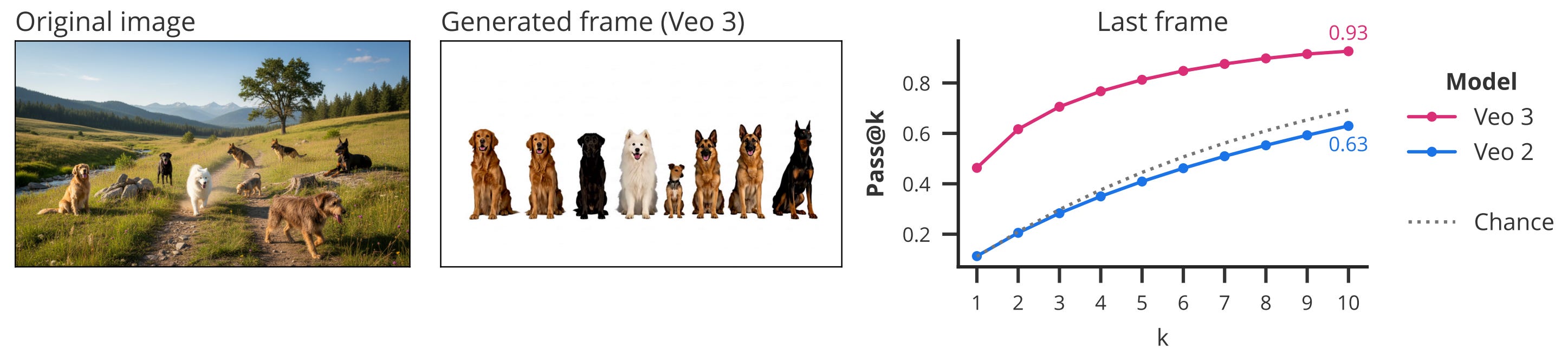
Object extraction. The researchers tested whether the model can perceive and manipulate all objects in a scene. They used a dataset with images containing between one and nine animals, and asked the model to extract these animals and line them up in a row with white space between them. By counting the connected components in the final frame as a proxy for correctness, Veo 2 performs close to random chance on this task, but Veo 3 achieves up to 93% accuracy (pass@10)!
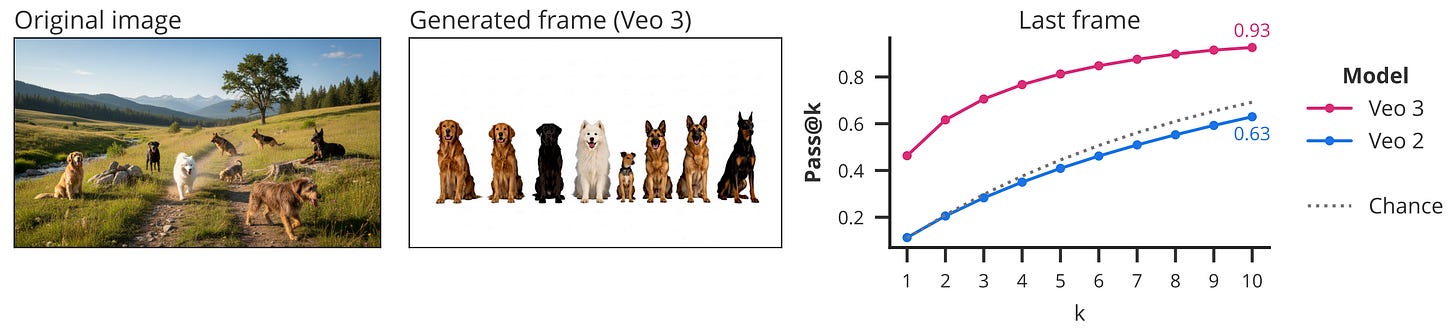
Image editing. It’s a classic editing request, like adding/removing objects or changing their appearance. Veo has a strong bias for animated scenes and tends to introduce unintended changes like camera and subject movement, but is still able to accomplish meaningful, precise edits. Curiously, no comparison with Nano Banana here, as it would smoke Veo pretty badly.


Reasoning
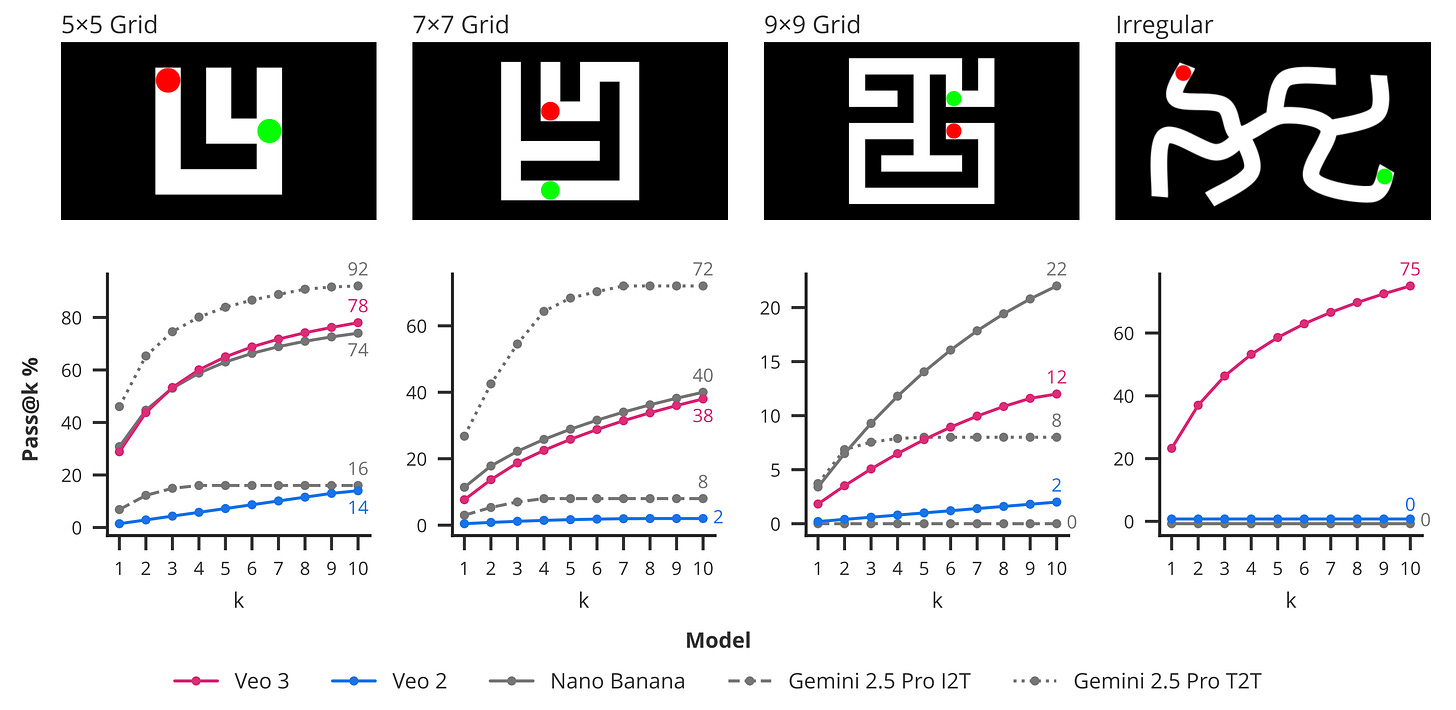
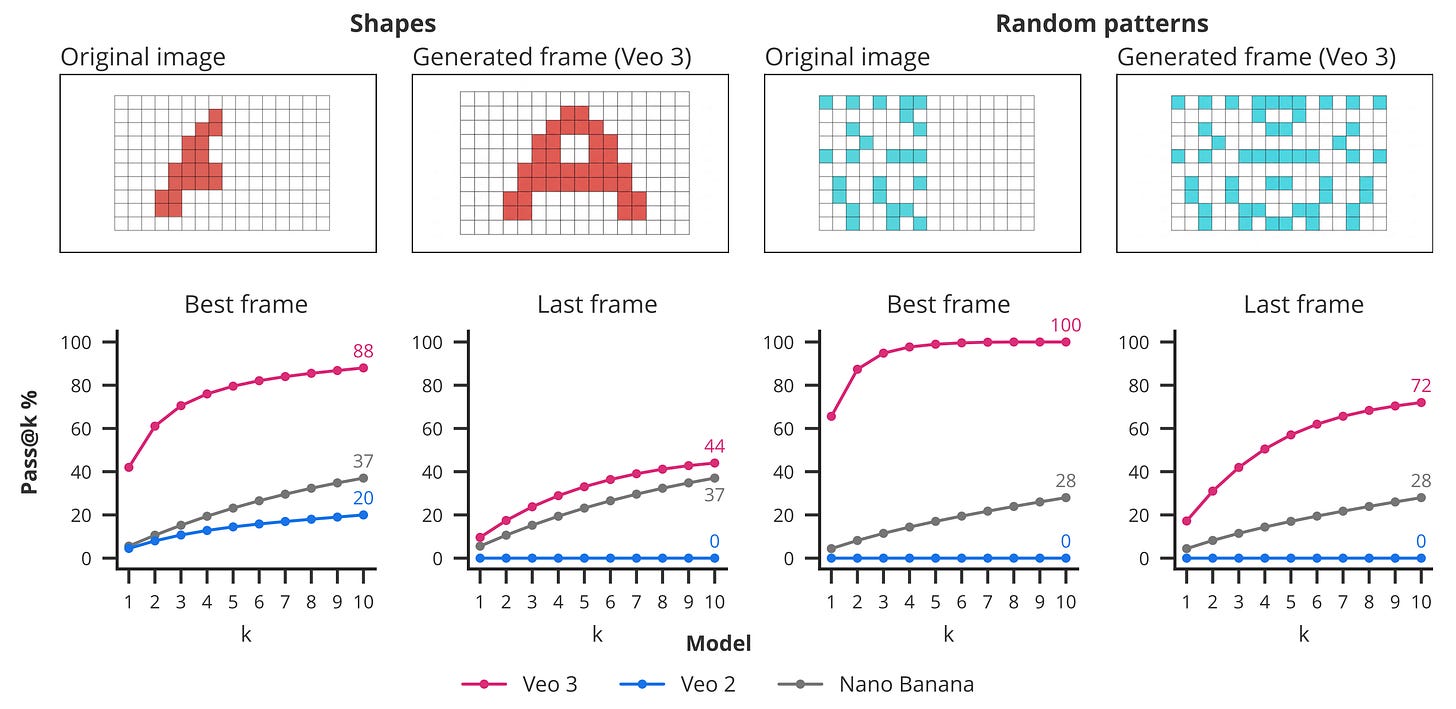
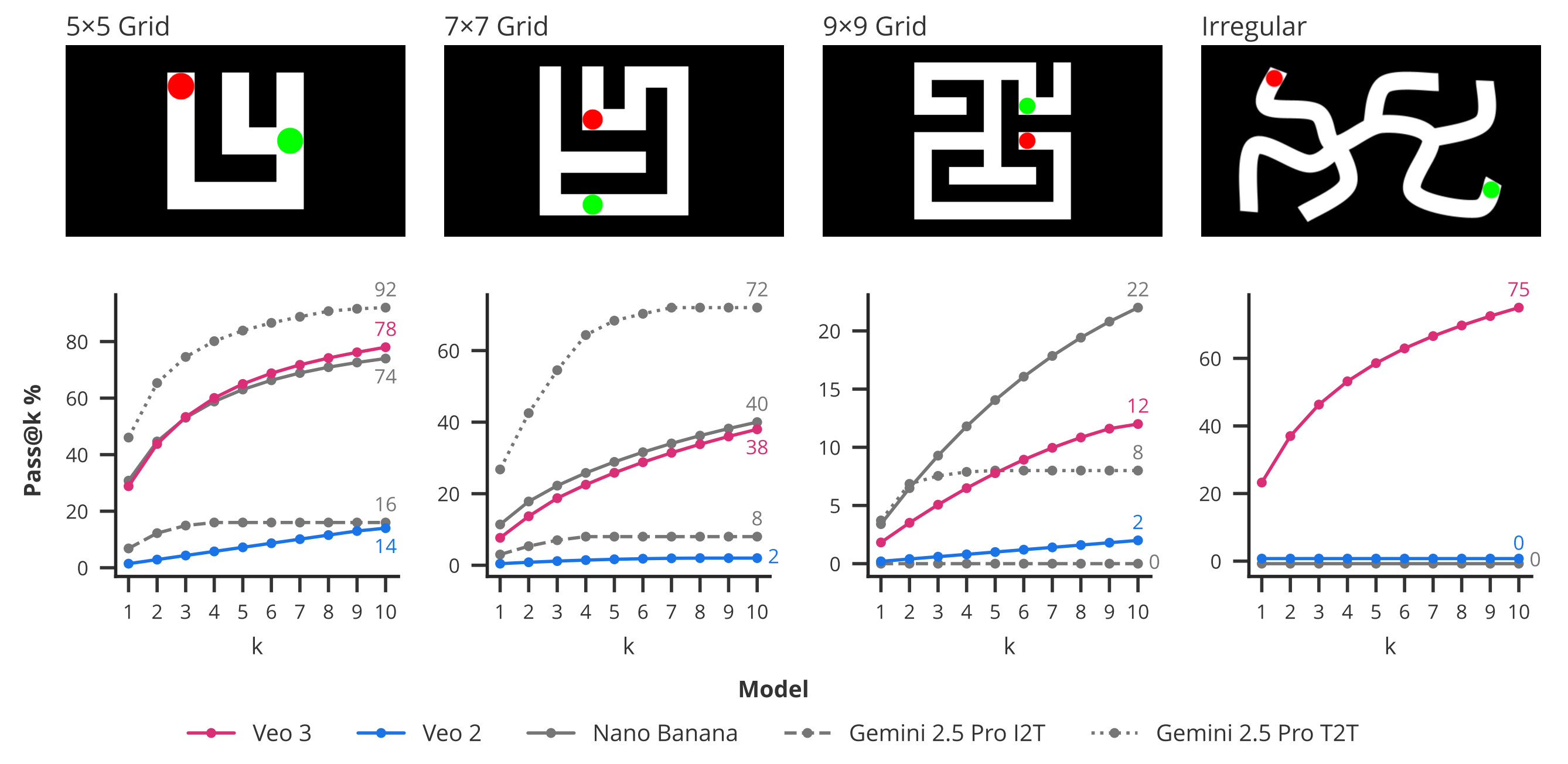
Maze solving. Given a visual maze, the task is to draw a path from start to finish without crossing any walls. This is a strong sign of reasoning abilities, as it requires planning and potential backtracking, not just plain pattern matching. The authors mention that Nano Banana fails on irregular mazes, and also compare to Gemini, representing the moves and maze in text form.
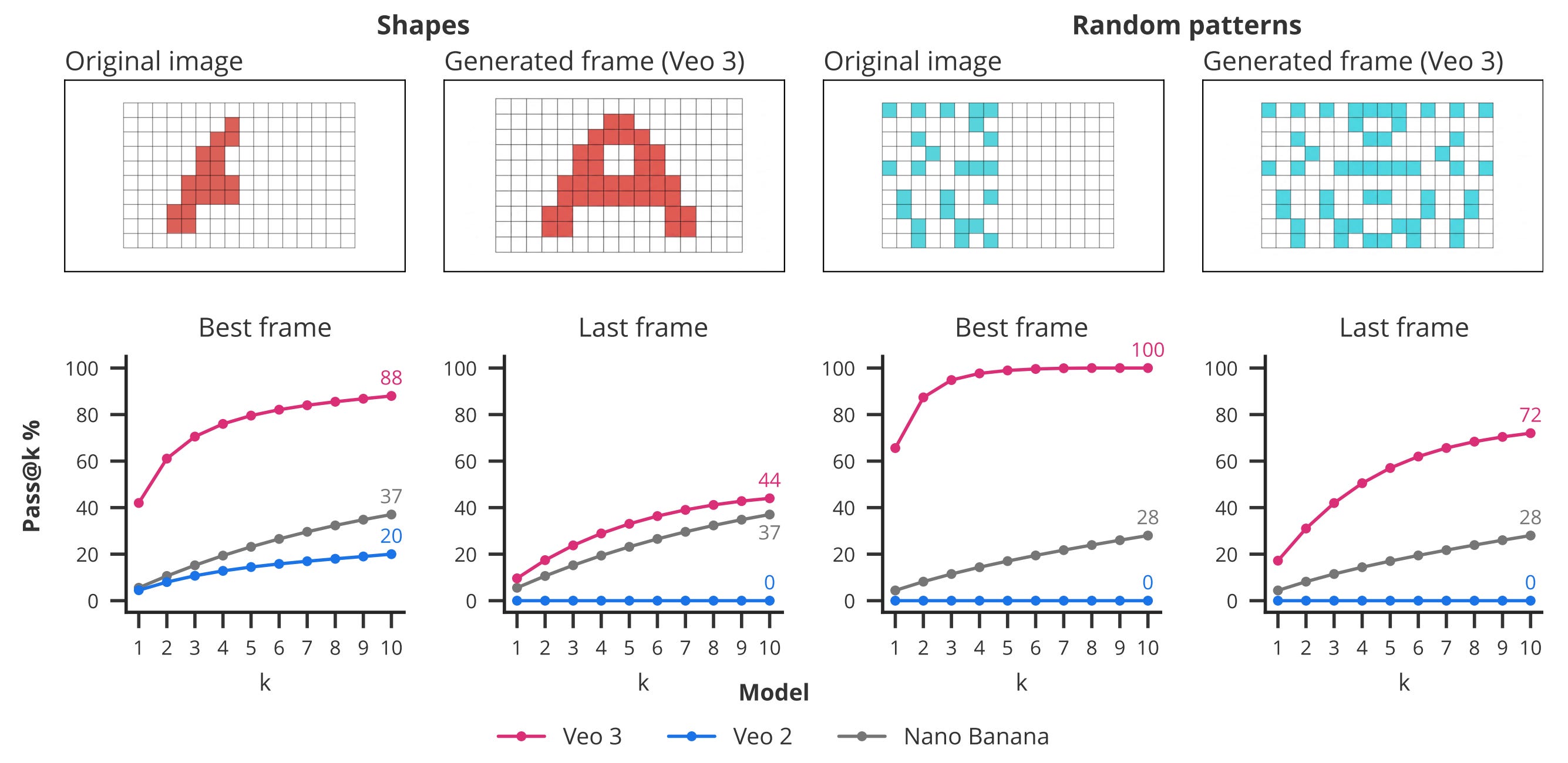
Visual symmetry. This one is about completing a pattern to be symmetrical. The inputs are sampled from a custom dataset of regular forms, such as hearts or letters, as well as random patterns. Surprisingly, Veo 3 outperforms Veo 2 and Nano Banana by a large margin.
Visual analogies. These puzzles test a model’s ability to understand transformations and relationships between objects, and represent a form of abstract reasoning. Concretely, the model is prompted to fill the missing quadrant of a 2×2 grid to complete the analogy “A is to B as C is to ?”. Veo 3 correctly completes examples for color and resize. However, it performs below chance on reflect and rotate analogies, indicating some systematic bias.


Other capabilities
These were only a small set of experiments that were run and measured quantitatively. However, the qualitative results cover many more areas. You should definitely check the official website and play around with all the video results!
Among my favorites, there are super-resolution, deblurring, rigid and soft body transforms, simulating gravity, novel view synthesis, 3D-aware reposing, and execution of dexterous manipulations.

A set of failure cases is also reported at the bottom, which makes it really funny. Similar to the way LLMs sometimes hallucinate facts, these models can produce strange physical errors or completely fail to follow the instructions.

Conclusions
Why is this paper relevant? Basically, it suggests that we might be on the verge of a unification in computer vision. Just as LLMs merged a wide range of tasks, video generation models might soon rival some specialized systems in areas such as segmentation, detection, tracking, and more. The model knows what and where a subject is, and it just needs to output that knowledge in a useful format.
Closing off the year, image generation is practically solved. It has already achieved perfect photorealism and text rendering, complex prompt adherence, and high subject consistency. Next year, video generation will follow right behind. And as these models become cheaper, simulators will become the de facto standard for generating labeled data and zero-shot problem solving. Start building!
Thanks for reading, happy holidays if you celebrate those, and see you next week for an incredible recap of the year, along with what to expect from Machine Learning with a Honk in 2026. Bye!
References
[1] Video models are zero-shot learners and reasoners
[2] Language Models are Few-Shot Learners
[3] PaliGemma 2 mix: A vision-language model for multiple tasks
[4] Veo: a text-to-video generation system
[5] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Didn't expect the 'GPT-3 moment' analogy for video models, but it makes so much sense now that you say it. The way Veo 3 is described, it really does feel like computer vison is finally catching up in the zero-shot reasoning game; guess my social media feed is about to get even more confusing.