
53. Initializing Models with Larger Ones
How to inherit weights instead of training from scratch


Introduction
Training a neural network from scratch is expensive, and in this era where powerful pretrained checkpoints are available off the shelf, it is the exception rather than the rule. But here’s the catch: this only works if you can find a pretrained model of the right size for your needs!
If you are training a small custom model for a personal project or trying to shrink a big one down to meet your tight inference constraints, you may be out of luck and find yourself back to square one: random initialization. While with enough data and compute, this is not a problem in practice, it still feels wasteful to ignore the larger pretrained models that already exist.
So, how do we leverage them for a better initialization? This is the question that “Initializing Models with Larger Ones” [1] asks, and the results show that all those computing hours don’t have to go to waste. Let’s dive in!
Method
The core idea is very intuitive: instead of initializing a small model randomly, we can inherit weights directly from a larger pretrained one. To clarify, here we are JUST seeking a smarter starting point wherever there is no better alternative, and then we can proceed as usual with our training. Especially if we are talking about shrinking foundation models, distillation is what should probably follow.
To give a concrete example, let's say you want a 5M parameter ViT-Tiny version of DINOv3 [2]. The smallest model Meta provides is ViT-Small at around 22M parameters, so you will need to train your own. And since you will be running distillation anyway to transfer the features from a larger DINOv3 model, the question becomes: what is the best initialization we can give our ViT-Tiny?
The answer lies in how modern neural network architectures are built. Models like ViT, ResNet, and ConvNeXt follow a modular approach where the same kind of layers are stacked repeatedly. This makes it easy to create families of models that share the same building blocks and only differ in width and depth. This is exactly what makes weight selection tractable, and the authors break the process down into three steps: layer selection, component mapping, and element selection.
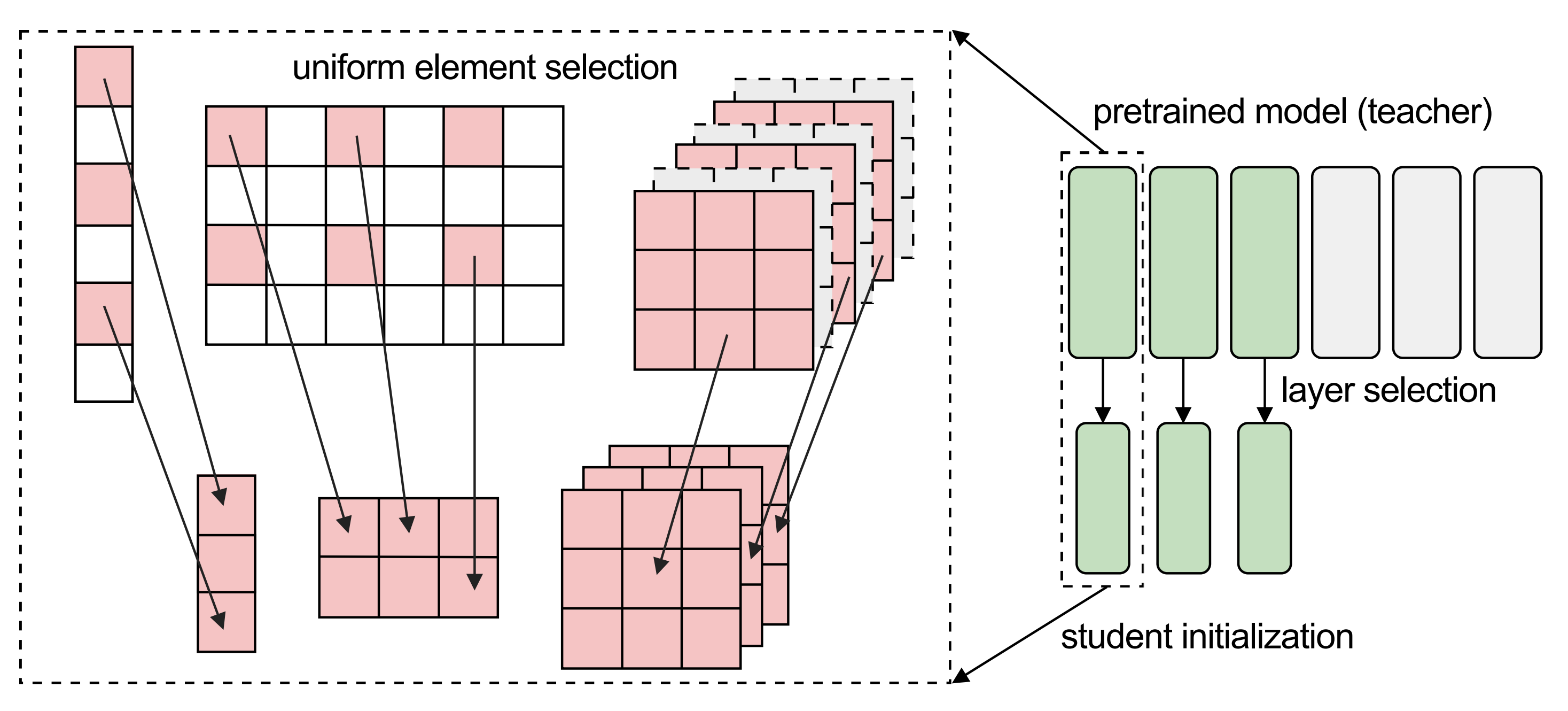
1. Layer selection
For isotropic architectures like ViT, where every block has the same structure, possible layer selection strategies include taking the first N layers, the middle N, the last N, or evenly spaced ones. The paper finds that picking the first N layers works best in most cases, and last-N performs the worst.
The intuition is that earlier layers are closer to the shared input and capture more general representations. For hierarchical architectures like ConvNeXt, which uses multi-scale stages, first-N selection is applied within each stage independently, taking the first N filters.
2. Component mapping
From the previous step, we have a layer-to-layer mapping between teacher and student, so the task reduces to initializing one student layer from the corresponding teacher layer. Since models in the same family often share an identical set of components that only differ in width, there is no ambiguity in how they align.
3. Element selection
The final step is deciding how to subsample the weight tensors of the teacher to fit the narrower dimensions of the student. The paper compares several strategies: uniform (evenly spaced dimensions), consecutive (a contiguous block), and random (with consistency across layers and without). The key finding is that the specific strategy does not matter much, as long as the same indices are used consistently across all weight tensors.
It is worth noting that uniform selection and consecutive selection inherently preserve consistency, as they are both special instances of random selection with consistency. The explanation lies in the residual connections used by practically all modern models: a neuron that is selected in one layer needs to be selected in every other layer as well, otherwise the additions in the residual stream no longer make sense.

Cool, so now we have an answer: select the first N layers from the teacher to reduce the depth, pick a consistent subset of weights from each component to reduce the width, and use that as your initialization.
Practical tips
A couple of practical tips from the paper are worth keeping in mind when performing this procedure:
First, select a teacher model that is as close as possible to the size of the student. For example, initializing a ViT-Tiny from a ViT-Small outperforms starting from a ViT-Base or ViT-Large. A larger teacher means a higher ratio of weights must be discarded, resulting in more lost information, even if the larger models outperform the smaller ones.
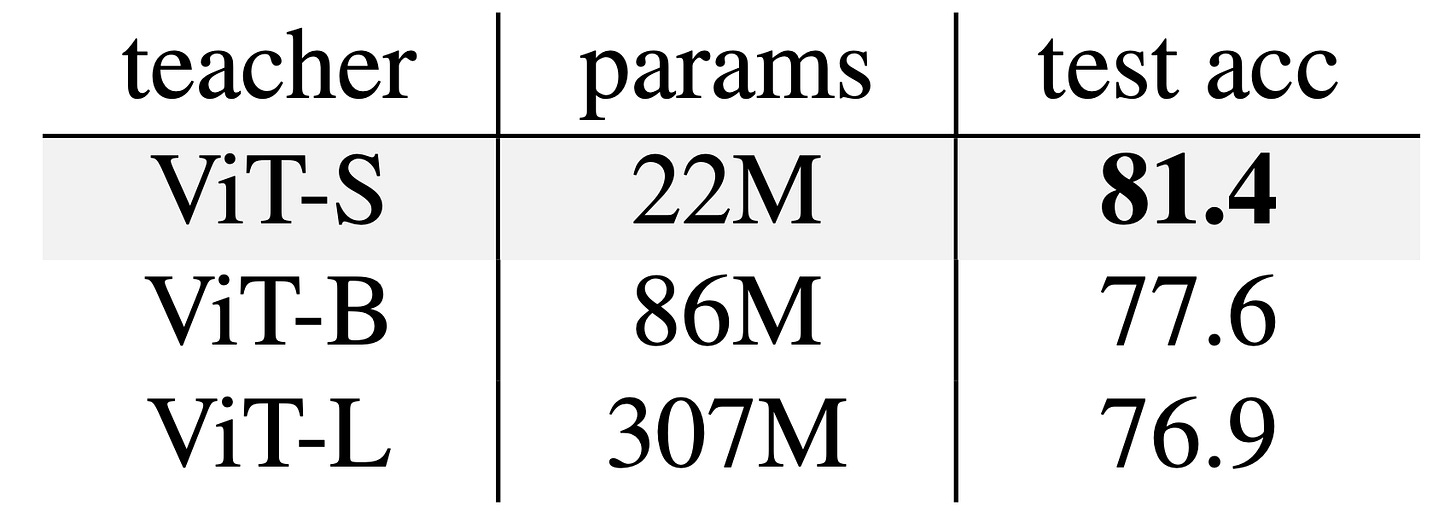
Distillation to ViT-Tiny: a smaller teacher provides better initialization. Second, weight selection plays well with knowledge distillation. The two are complementary: using weight selection as the initialization for a distillation run consistently outperforms either technique on its own.

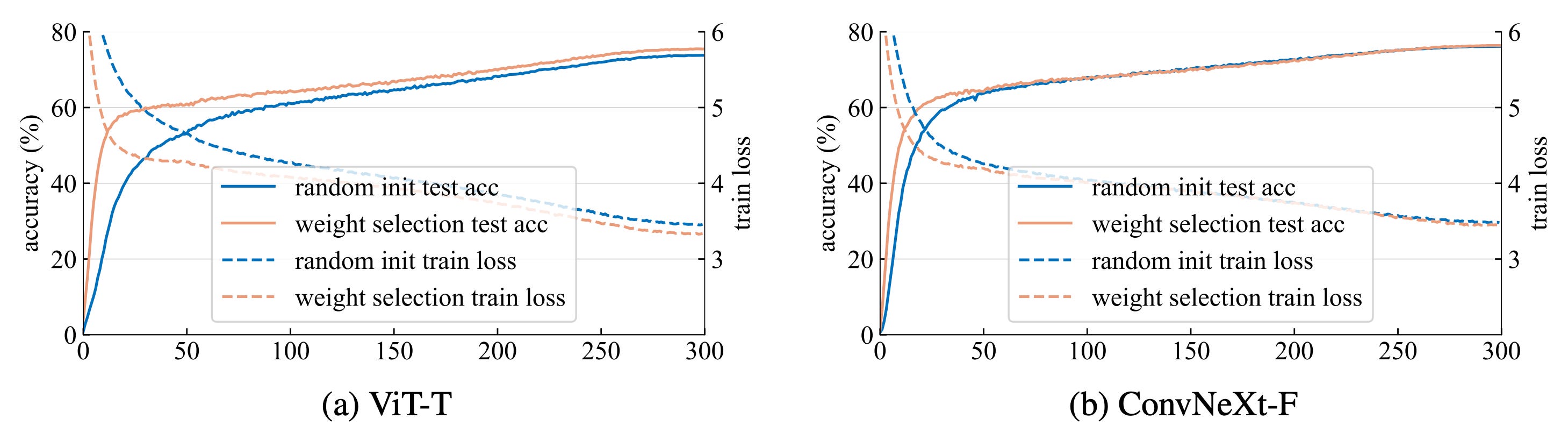
Weight selection can be combined with knowledge distillation to achieve the best performance. From [1]. Third, expect the biggest gains on small datasets. Weight selection is especially effective when data is scarce, and this is particularly relevant for ViTs, which are known to struggle when trained on small datasets from scratch. This can be seen through linear probing over the frozen initial representations, where weight selection produces somewhat meaningful features before any training, as well as through strongly reduced training times needed to reach a target accuracy.
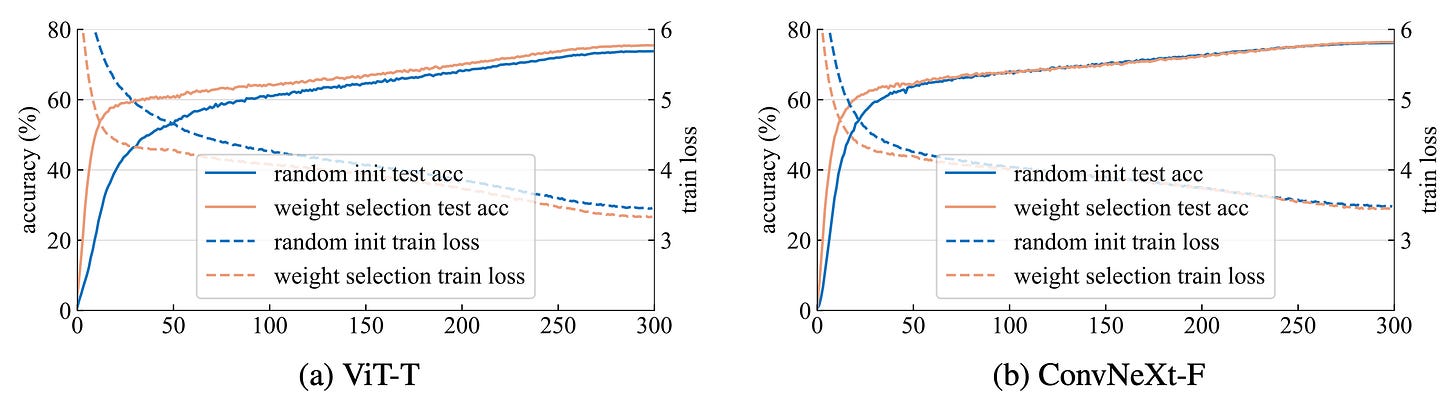
ImageNet-1K training curves. ViT-T and ConvNeXt-F initialized with weight selection from larger models outperform random initialization, especially with fewer training epochs. From [1].

Tutorial: weight selection for a ViT-Tiny
Transformers are probably the most natural use case for this paper, given how well-established the ViT model family is and how many pretrained checkpoints are available at different sizes. Let’s say you want to train a ViT-Tiny for a project where inference cost matters. Here is how you would approach it, using the uniform element selection strategy:
Look for a pretrained ViT-Small or ViT-Base checkpoint. This applies the rule of picking the closest size available to the target mentioned above. Some model families, like V-JEPA 2, may start with even larger variants [3], so be flexible here.
Select the first N layers. ViT-Tiny has 12 layers, the same as ViT-Small and ViT-Base, but with a smaller embedding dimension of 192 vs their 384 or 768. So layer selection is trivial here: take all 12 layers, no subsampling needed. If the smaller variant is, say, a ViT-Large, then pick the first 12 blocks.
Subsample the attention heads. ViT-Small has 6 attention heads and ViT-Base has 12, while ViT-Tiny has only 3. Each head has its own query, key, and value projection matrices, so selecting 3 heads simply means keeping 3 of these sets. Uniform selection picks every other head from ViT-Small, or every fourth from ViT-Base. Each projection must also be subsampled consistently to match the smaller embedding dimension, reducing it by half or by four. The output projection matrix, which maps all head outputs back to the embedding dimension, is then subsampled to keep only the mixing of the selected heads.
Subsample the MLP layers. Each transformer block contains an MLP that expands the embedding dimension by a factor of 4 before projecting it back down. Uniform selection picks evenly spaced neurons defined by the rows of the first projection and the corresponding columns of the second. The columns of the first projection also need to be subsampled consistently with the embedding dimension, so that the residual addition at the end of the block remains valid. For ViT-Small, the hidden MLP dimension is 1536, so we sample every other neuron to reach 768. For ViT-Base, the hidden dimension is 3072, so we sample every fourth neuron.
Train as usual. Use the result as your initialization and run your standard training recipe, or plug it into a distillation pipeline if you have a larger teacher available and a lot of unlabeled data. Compared to random initialization, you should expect better performance, especially in the early stages of training.
Conclusions
Training a model from scratch is not common today, but in edge deployment scenarios where fast and lightweight architectures are needed, sometimes building custom models is required. If you want a smaller version of a foundation model like DINO or V-JEPA, there is simply no pretrained checkpoint at the right size, and you are left to train your own (via distillation)!
This paper shows that extracting a subset of weights from a large pretrained model provides a superior initialization point for a smaller model in the same family. The key thing to remember here is consistency: the same indices must be used across all weight tensors, otherwise the residual additions will break. Thanks for reading, and see you in the next one!
References
[1] Initializing Models with Larger Ones
[2] DINOv3
[3] V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning