
61. CVPR 2026 Recap
Red rock mountains, lots of parties, and the latest in vision!


A conference a mile high
At the beginning of the month, the IEEE/CVF Conference on Computer Vision and Pattern Recognition (aka CVPR) 2026 took place in Denver, Colorado. With the convention center standing literally a mile high (yes, 1609m, I am American now 🇺🇸) in a city that ranks in the top 5% of highest places in the country, it was a completely different taste from the Bay, and I absolutely loved it!
In the landscape of scientific literature, CVPR ranks as the top venue in computer science and the number two publishing destination across all disciplines, sitting just behind Nature. To truly understand what this means, I had to check it out, and unlike ICCV, I think hosting it on the mainland made the expo portion super fun.
My goal was to treat it as a massive networking opportunity, and I wasn’t shy about it. Other than co-hosting not one but two private afterparties, I ended up spending lots of time at the Meta booth chatting with the authors of my favorite recent papers (DINOv3 and V-JEPA 2), met dozens of fans and friends in real life, and even got recognized by one of the authors of the best paper award: that made my day!
But enough talking. Today, we will go through the core trends and five cool papers found during the conference to give you a general overview of what’s happening out there. Enjoy!
Record numbers and 2026 hot topics
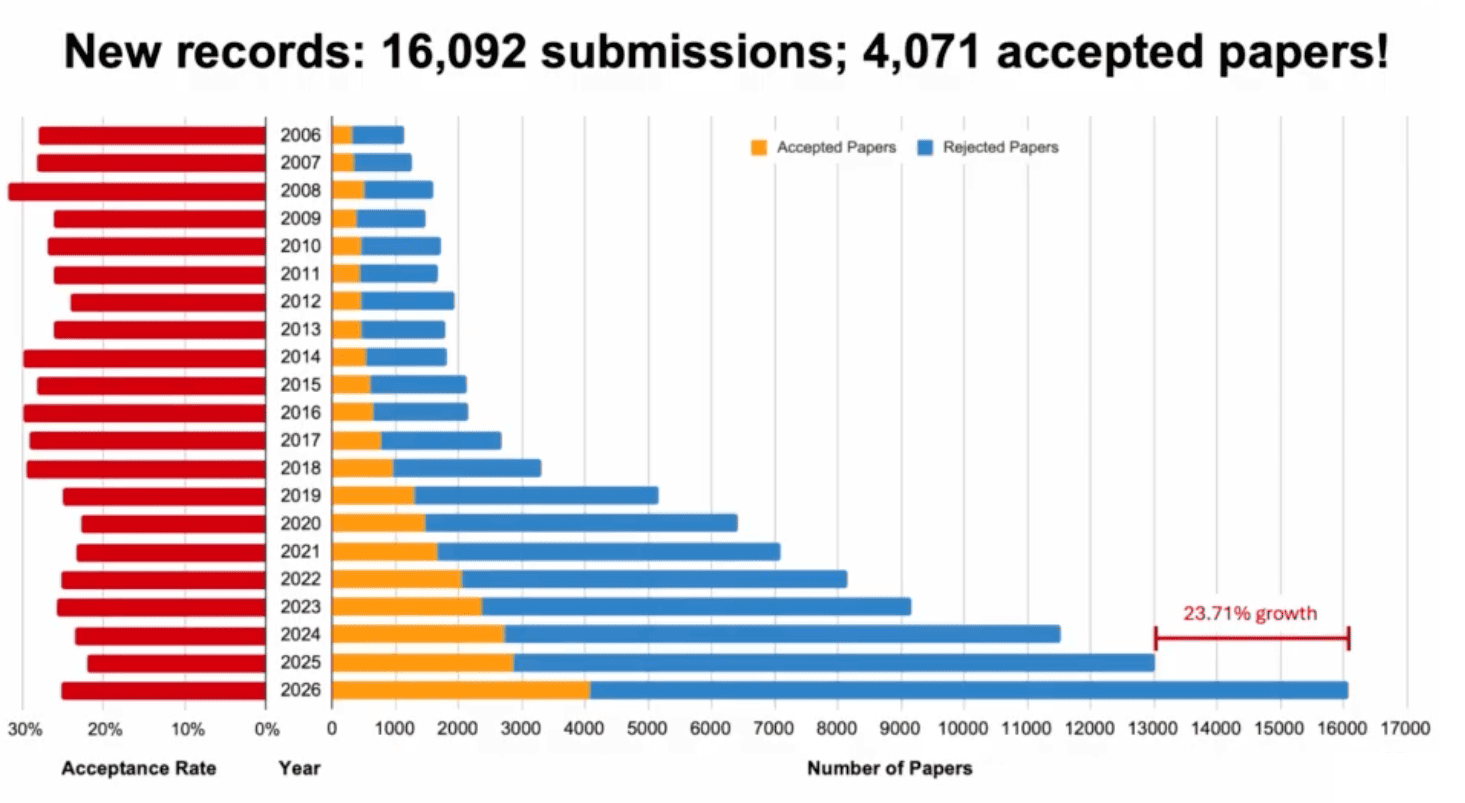
With no surprise, the conference broke every record: the number of submissions and accepted papers increased by 24% compared to last year, reaching a total of 16,092 and 4,071, respectively. The trend is… looking good?
When we look at the statistics of the submissions, we see that the research landscape has evolved slightly from ICCV. While image and video generative models are still by a large margin the most common area of research, VLMs and multimodal learning surpassed 3D reconstruction in this edition, claiming the second and third spots on the leaderboard. Also, computer vision for robotics saw a noticeable increase in relative ranking, while human modeling experienced a significant drop.
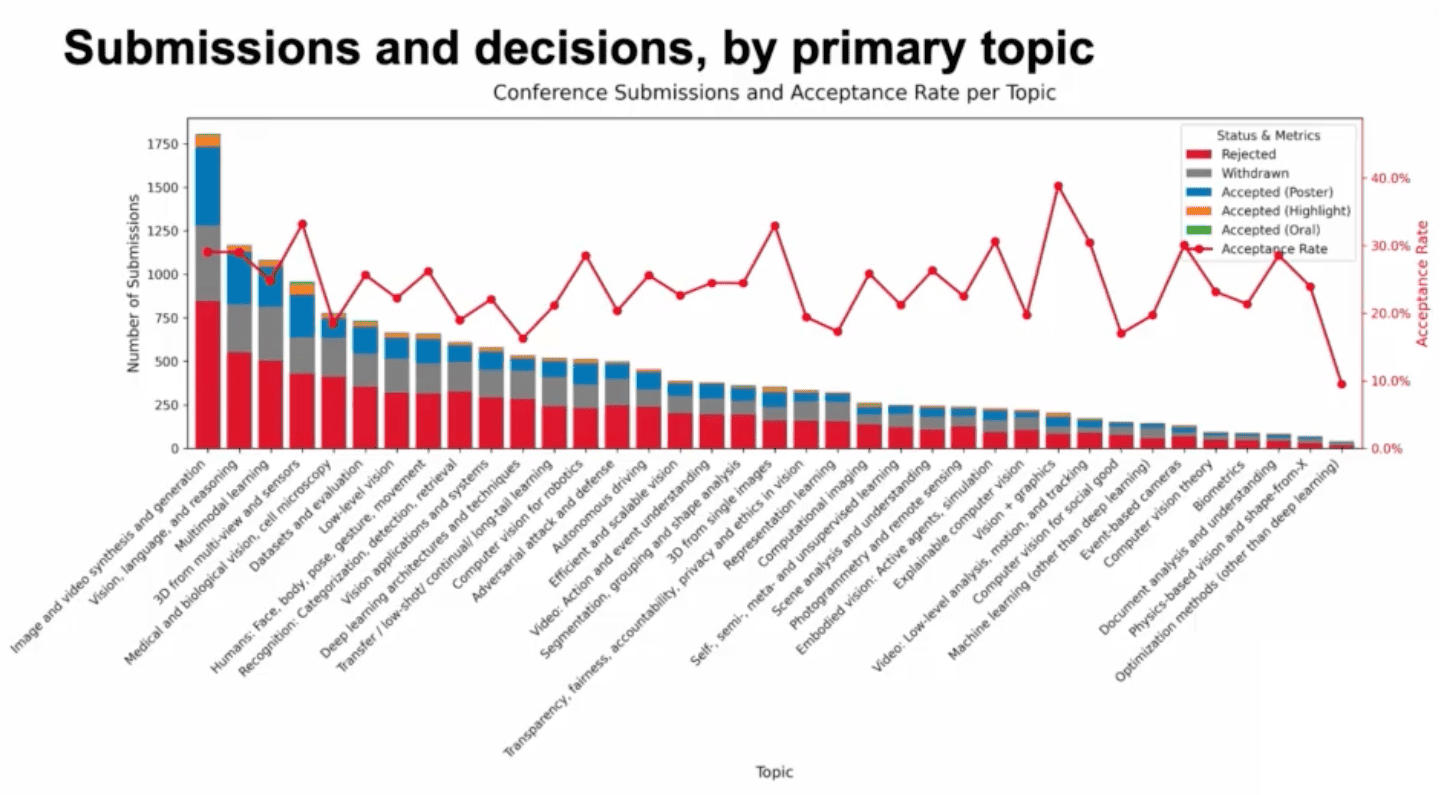
Because the submitted papers represent work from over six months ago, we are essentially looking at the downstream impact of big tech and research labs dropping powerful open-source image and video generators over the past year. Once again, world models (and VGI) were by far the biggest buzzwords of the event, with some impressive live demos from the industry right at the booths (loved the Tesla real-time driving video game), but not yet transferred to the posters. Give it six more months.
Another interesting aspect is the breakdown of the compute resources survey, which was mandatory for all submissions. The main takeaway was that acceptance correlated strongly with a higher GPU count. Why? More than training a larger model, running more experiments naturally increases the chance of discovering something that actually works. I couldn’t agree more based on my personal experience at work, and this was visible with almost all the award-winning papers coming from industry or industry collaborations.
Finally, the Test of Time Awards went to two of the most iconic works from 2016, which survived crazy times in AI:
ResNet [1], which introduced residual skip connections and allowed neural networks to scale to hundreds of layers deep. Beyond being the most cited AI paper ever, it is one of the few that successfully translated across every single domain and architecture. Safe to say it isn’t going away anytime soon!
YOLO [2], which reframed object detection as a single regression problem. Fast, lightweight, and super easy to train, it has paved the way for modern real-time computer vision and is still the starting point for every vision practitioner and the most widely used object detection system in industry.
Now, let’s dive into five one-minute pitches for the cool papers of the conference that I personally found interesting.
Native and Compact Structured Latents for 3D Generation [3]
This paper introduces TRELLIS.2, the evolution of the popular open-source model from Microsoft, designed for high-fidelity 3D generation. It also received the best student paper award. In practice, you pass an image, and you get a super detailed 3D model in return (including interiors!) that can then be natively decoded into any format like a mesh, 3D Gaussians, or a Radiance Field.

What used to be days of work for 3D artists, today is commoditized as 10 seconds of inference with a 4B transformer model. Without going too much into the details, the generation process unfolds in multiple stages, as established in this line of work by the major players (Tencent and Microsoft). First, we predict the geometry layout of the 3D object, and then we proceed to texture and curate it, including the generation of complex material properties.

High-quality generation is all about training models in an efficient latent space. TRELLIS.2 introduces a new sparse voxel representation called O-Voxel encoding both geometry and appearance of meshes, which does not break down with complex data. Then, a Sparse Compression VAE moves this to a compact structured latent space where generation happens, bypassing the cubic memory scaling of a naive 3D pipeline and allowing this model to produce up to a 1536³ resolution at test time. Try it out next time you want a production-ready 3D asset!
Sensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving [4]
This paper is extremely cool. It introduces Sensor2Sensor, a novel generative paradigm from Waymo designed for cross-embodiment sensor conversion in autonomous driving. Basically, the input is an “in-the-wild” monocular video from a dashcam or a phone, and the output is a multi-sensor log with 8 camera views plus synchronized LiDAR point clouds.

This is an attempt to reverse engineer the data collection process, and combined with state-of-the-art video generation, can be used to train autonomous vehicles on rare, long-tail scenarios without costly real-world driving fleets. Unfortunately, the system is not open source, but it shows what can be achieved by a small generative model of 250M parameters when you have just 100k of 10s driving clips and a lot of compute.
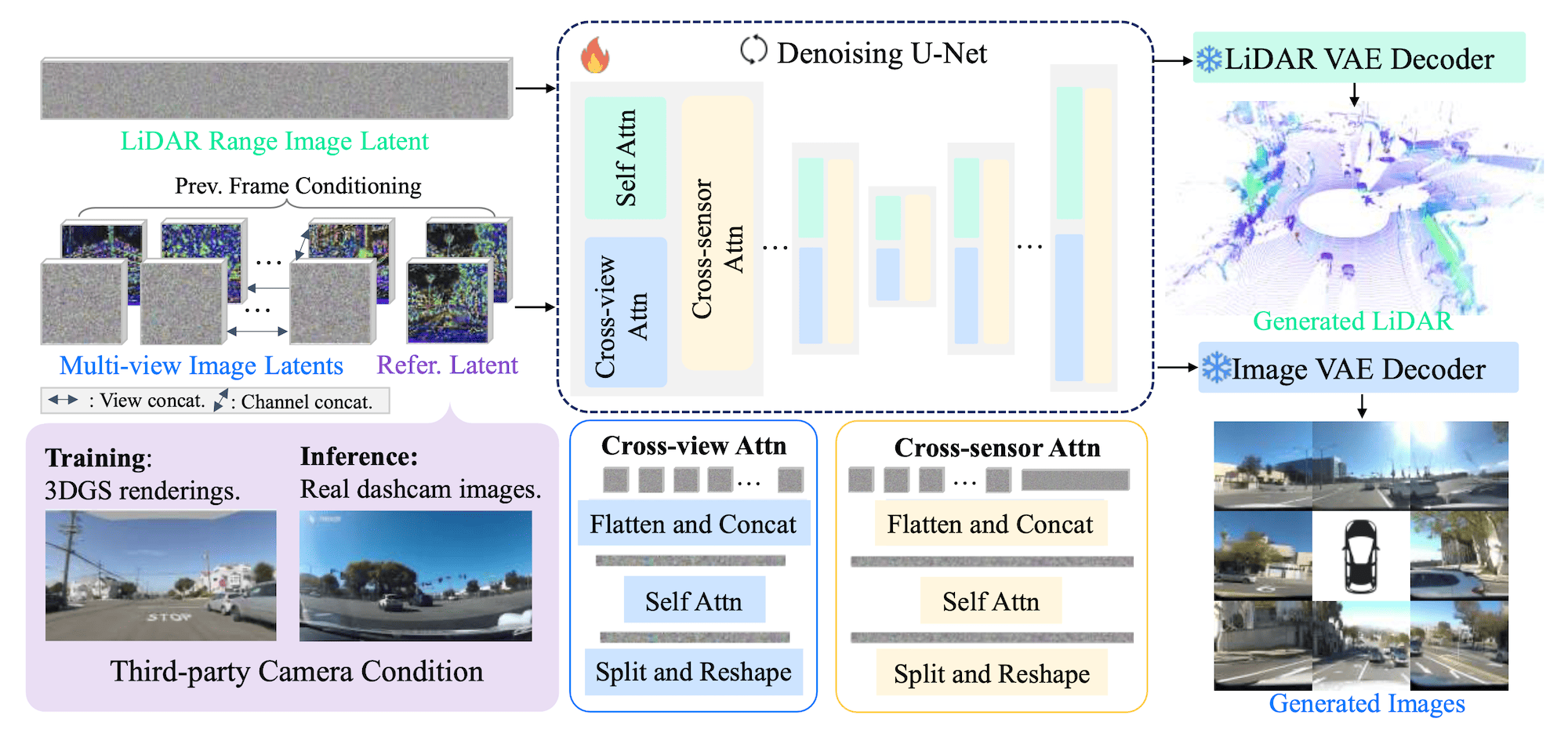
The core modeling architecture is a conditional multi-stream latent diffusion framework running separate, modality-specific VAE and U-Net that, however, interact during generation. The input monocular video acts as a conditioning signal, and the temporal aspect is also baked in via autoregressive generation. Ground truth is provided via reconstruction by a dynamic 4D Gaussian Splatting (4DGS) pipeline, and rendering according to a novel view. I hope one day to train something like this!
INSID3: Training-Free In-Context Segmentation with DINOv3 [5]
This paper introduces a training-free framework for one-shot segmentation. In other words, you annotate a single visual example of your dataset, and for any other target image that you pass, you get a precise segmentation mask out, like below.

INSID3 handles multiple domains from object parts to medical images and aerial views without requiring any downstream fine-tuning or secondary models like SAM. How? Because DINOv3 has seen all of these, and its features are heavily semantic.
What it takes to make this work, though, is noticing that dense features suffer from a systematic positional bias that screws up feature correspondences across different images. In other words, positional information injected at the beginning of the ViT persists in the output patches and makes points in similar regions always similar, even though the content does not match semantically.

The authors observe that this positional bias forms a stable, low-dimensional subspace within the representation, and this can be estimated by passing a simple noise image through the encoder and applying singular value decomposition. So, during inference, both the reference and target feature maps are projected onto the orthogonal complement of this subspace, removing the positional bias.
Region-level clustering and nearest neighbor matching to the target mask complete the pipeline, providing a massive speedup for your annotation workflows. Give it a try!
Learning Convex Decomposition via Feature Fields [6]
Convex decomposition breaks 3D shapes into a union of convex bodies, which are used, for example, to accelerate collision detection in physical simulation. Doing this algorithmically is an NP-hard problem, but fortunately, neural networks can come to the rescue. How do we train one to do convex shape decomposition?
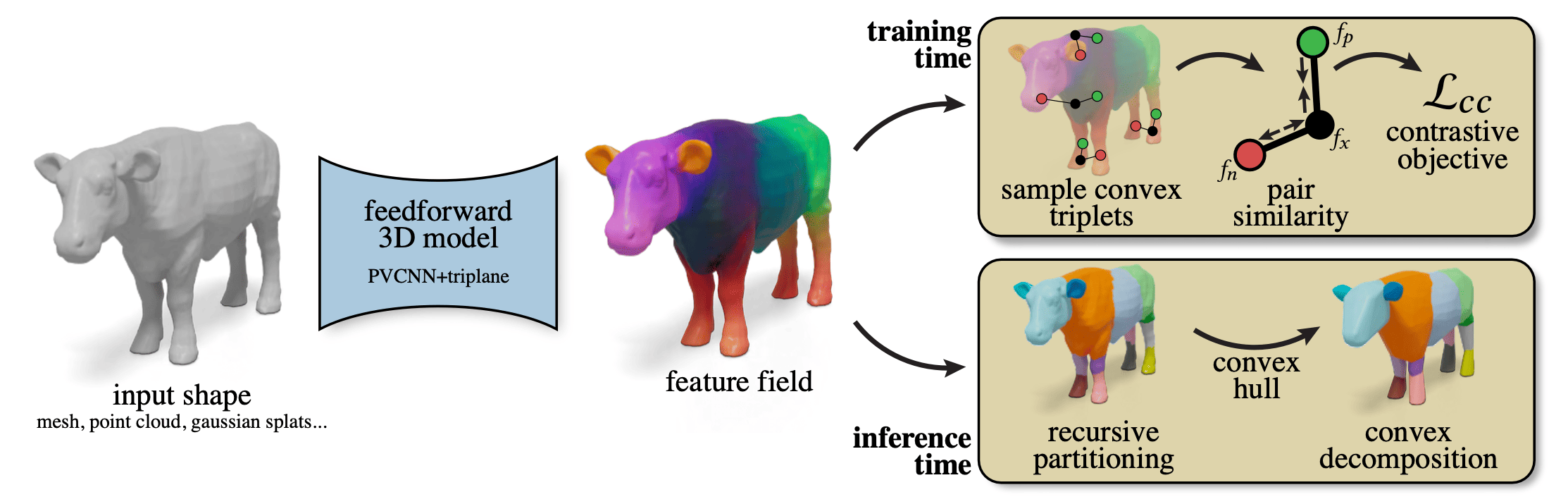
Simple! We train a feed-forward model to assign to each surface point a vector, living in a continuous high-dimensional space, embedding the property that we desire. In this case, the objective is derived directly from the definition of convexity: if a straight line segment connecting two surface points stays entirely within the object’s solid volume, they form a convex pair. Otherwise, we say they must be associated with two different parts.
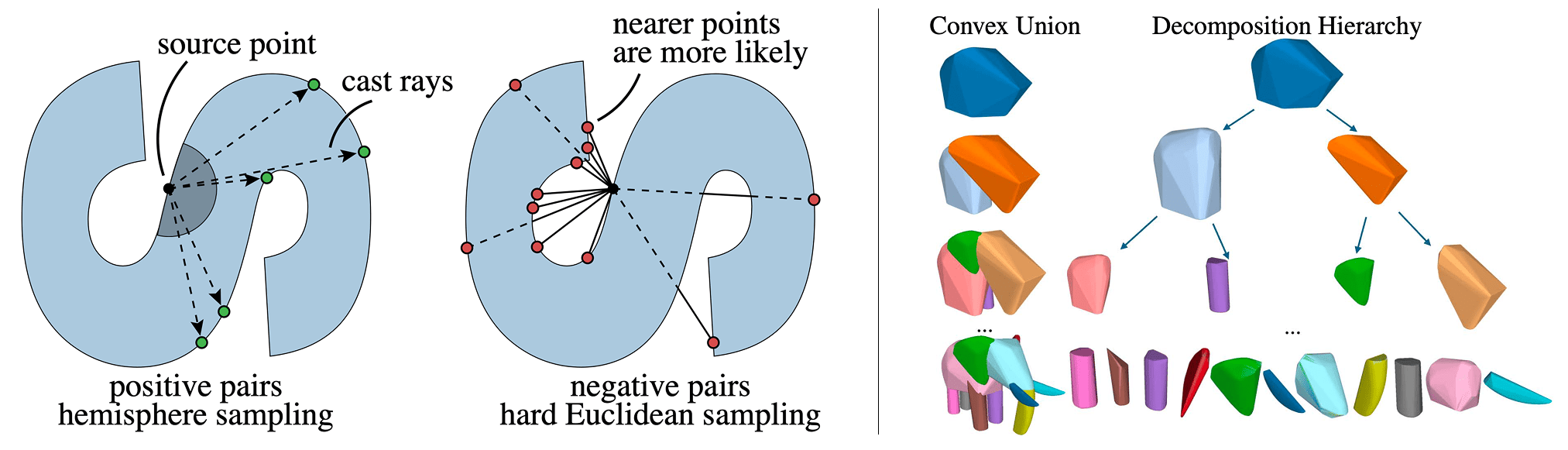
Using a triplet loss, the high-dimensional vectors associated with each point are optimized so that convex pairs are pulled closely together in feature space, while non-convex pairs are pushed apart. This self-supervised pipeline requires no labels, just 3d shapes, and works like magic with an existing 3D encoder architecture.
After the model is trained, the continuous feature fields can be clustered at inference time using a simple recursive strategy to extract the final convex components. If a cluster exceeds a specified concavity threshold, a binary clustering step splits the component into two subcomponents.
I found this paper interesting because it shows that elegant ideas with solid practical application can still be found, and they can absolutely obliterate the performance of prior works. The reason once again relies on training with no labels, which has fundamentally no data scalability limits.
SeeGroup: Multi-Layer Depth Estimation of Transparent Surfaces via Self-Determined Grouping [7]
Last but not least, a fun and interactive paper about depth estimation. Monocular depth has always been ambiguous when multiple layers of transparent surfaces are present, because a single camera ray hits multiple overlapping depths at once. The usual convention these days, as models are trained exclusively on synthetic data, is to always take the impact with the first surface, whether it is transparent or not.
But if we have full control over the synthetic scenes, why not export the depth of the second reflection, or the third, and so on? Why not have a knob that can be adjusted at training and inference time to give us see-through depth?
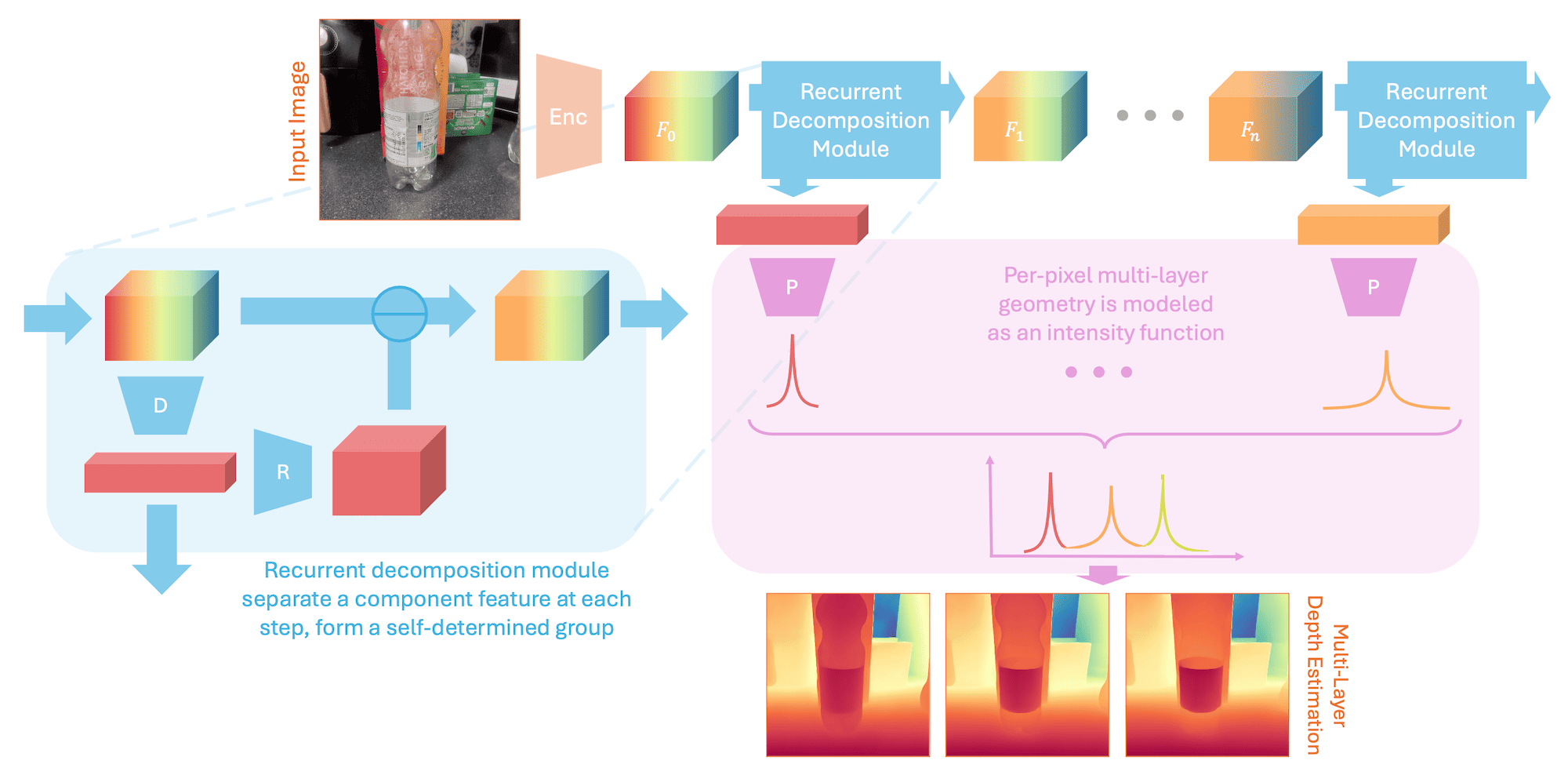
That is what the authors of LayeredDepth did to build the synthetic depth dataset used here, which, honestly, is the most valuable asset of the paper itself. Apart from that, the model introduces a new training paradigm where, instead of predicting absolute depth values, the network learns to output a continuous spatial intensity function parameterized as a max-mixture of Laplace distributions.
This is simple yet useful because it finally provides perception systems with the capabilities needed for safe navigation and manipulation. Overall, most of the work is in creating the dataset, but again, that is what real ML is about and what academia most of the time needs to be about as well.
Final thoughts
The papers I mentioned here are just a very small, biased sample of the enormous number of works presented at CVPR. Overall, I personally felt overwhelmed at times by how much stuff there was to see, and I am sure I missed some really good papers that I might discover only months later. If I do, you know where to find them!
Anyway, it felt really nice meeting lots of new people and some of you guys in person, and I want to conclude with a short critical thought. Walking around the posters and attending the orals, I noticed a strong correlation between papers that have long-lasting practical applications and the heavy backing of industry. It feels like it is getting increasingly harder to produce great vision work using only the compute and data resources available in academia, and I’m sure I’m not the only one thinking that.
Don’t get me wrong, academia still produces gems, and some examples are reported in this summary. But at the same time, there were hundreds of papers at the conference that were already outdated after six months due to the release of an image or video generator by some frontier lab, or even completely overshadowed by other CVPR papers from large tech companies on the same topic.
So is it worth attending such a conference if that’s the case? It is great for networking, no doubt, but to be up to date, you can certainly do that by following a bunch of people on social media or subscribing to a couple of newsletters. Keep this in mind if you are thinking of going, because maybe the expenses are a bit unjustified. Anyway, hope you liked the summary, and see you next time!
References
[1] Deep Residual Learning for Image Recognition
[2] You Only Look Once: Unified, Real-Time Object Detection
[3] Native and Compact Structured Latents for 3D Generation
[4] Sensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving
[5] INSID3: Training-Free In-Context Segmentation with DINOv3
[6] Learning Convex Decomposition via Feature Fields
[7] SeeGroup: Multi-Layer Depth Estimation of Transparent Surfaces via Self-Determined Grouping