


7. CLIP: Contrastive Language-Image Pretraining
Unifying representations for vision and language


Introduction
Traditional computer vision systems are designed to predict a fixed set of predefined object categories. While this set can be large — ImageNet, for example, contains 1000 classes — it is still fundamentally limited. When an object falls outside the training vocabulary or multiple subjects are in a scene, the model must either misclassify or struggle with ambiguity.
Open-vocabulary models aim to overcome this limitation by enabling recognition beyond a fixed set of labels. CLIP (Contrastive Language-Image Pretraining), introduced by OpenAI in 2021 [1], revolutionized the field by learning visual concepts from natural language supervision. Its influence on multimodal learning remains strong today, with its encoder still widely used as part of more complex systems.
Motivation
The core idea behind CLIP is to learn a shared representation space for images and text, bridging the gap between vision and language. For instance, an image of a goose and the phrase “an image of a goose” are assigned nearly identical embeddings, meaning they represent the same concept regardless of the input modality.
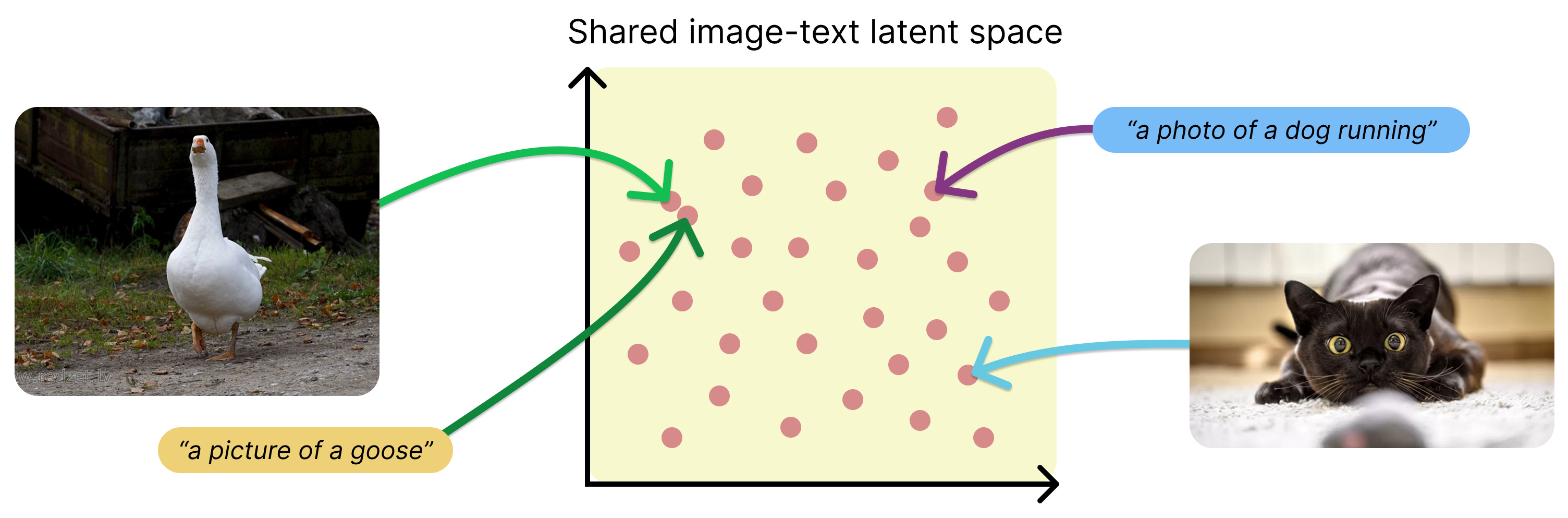
This approach, in a way, mirrors how humans perceive. Rather than processing images, text, or sounds in isolation, our brain associates them as different sensory manifestations of the same idea. This allows for a more holistic understanding, where multiple modalities reinforce and enrich the perception of concepts.
Dataset, architecture, and training
How to train a system like this? The answer is large-scale contrastive learning — similar to what was discussed in the previous post — but this time applied to images and text within a multimodal embedding space. Let’s break it down step by step.
1. Collecting large-scale image-text pairs
Combining existing labeled image datasets is not scalable, as they are limited in size and label diversity. Thus, a diverse dataset must be constructed from the internet.
While scraping billions of images is relatively easy, most lack high-quality captions and their metadata is often unrelated to the actual content. Imagine looking at the description of an image only to find “20240212_153721.JPG”. That’s not going to help…
As noted in the paper, after filtering an existing web dataset of 100 million images to keep just those with natural language titles or descriptions in English, only 15 million would remain. This illustrates how much noise exists in raw image-text data, but it is the only way to proceed.
The authors managed to construct a dataset of 400 million image and text pairs from a variety of sources on the internet, with the property that the text includes one of a set of 500,000 queries. These text descriptions can come from alt-text on websites, photo captions from social media, news articles paired with images, and so on.
2. Dual encoder architecture for image and text processing
CLIP consists of two separate neural networks trained simultaneously, one for encoding images and the other for encoding text. Once trained, each network can also be used independently, as explained at the end.
For the image encoder, responsible for converting an image into a high-dimensional vector encoding semantic features, the authors experimented with two model families: ResNet [2] and Vision Transformer (ViT) [3].
The latter is an adaptation of the original Transformer [4] architecture to images, where each image is divided into a sequence of small square patches and processed similarly to a sequence of word tokens. In the end, the authors found that the ViT trained faster and performed better.

As a text encoder, a Transformer-based language model is used with no surprise, with the input length capped to a short paragraph. This processes text descriptions and converts them into an embedding that captures their meaning.
Both encoders produce embeddings of the same dimensionality — this is achieved with linear projection matrices on top — to enable direct comparison and interaction via operations such as a dot product in the joint embedding space.
3. Contrastive learning: aligning images and text
Training a system to predict the exact words of the text caption would be extremely challenging. The clever trick is solving the easier proxy task of predicting only which text is paired with which image, and not the exact words of the description.
So, given a batch of N (image, text) pairs, CLIP is trained to maximize the cosine similarity of the image and text embeddings of the N real pairs in the batch, while minimizing the cosine similarity of the embeddings of all the other pairings.
This is achieved by optimizing a symmetric cross-entropy loss over the similarity scores, so that correct pairs get pushed to 1 (perfect alignment in the embeddings space) and dissimilar pairs get pushed toward 0 (orthogonality).
Think of it like a giant memory game — matching pictures to the right text while avoiding mismatches. Over time, CLIP learns to associate textual concepts with images, even for things it has never explicitly seen before.
Due to the large size of the dataset, overfitting is not a major concern, and CLIP is trained from scratch without initializing the image encoder with ImageNet weights or the text encoder with pre-trained weights.
Applications
Once the shared image-text space is learned, several interesting applications become possible. Here’s a list in no particular order:
1. Zero-shot classification 📊
The broad exposure to diverse visual and textual content enables the model to learn great features and perform zero-shot classification by selecting the class embedding most similar to the input image embedding. Essentially, this is like asking “Among this set of labels, which one best aligns with the image?” and solving classification as a similarity-based matching process.
Pro tip: neither the image nor the text is necessarily fixed here. It is possible to run the same set of queries with an augmented image (e.g. flipped) and alternative text variations. For example, one can query using “An image of {label}”, “A photograph of a {label}”, or more domain-specific prompts like “A photo of a {label}, a type of pet”. This technique serves as a form of free ensembling, often leading to a performance boost.
2. Cross-modal retrieval 🔄
A shared embedding space allows querying in one modality and retrieving results in the other. For example, a user can retrieve images using a text description or surface relevant textual content for a given image. This finds applications in search, recommendation systems, and accessibility tools.
3. Aesthetic ranking 🎨
CLIP is still widely used today in the image generation literature to evaluate the alignment between a generated image and the prompt passed to the model, a metric known as the CLIP Score. As simple as a dot product can be, it is highly correlated with human judgment and can be run at scale.
4. Feature extractor 🧩
Since CLIP consists of two separate encoders trained together, each component can be used for downstream tasks, as both offer valuable and robust features due to their exposure to a diverse and large-scale dataset during training. For instance, the image encoder can be initialized as a pretrained model for standard classification. Similarly, systems like Stable Diffusion reuse the CLIP text encoder to transform the input text prompts into embeddings used to guide image generation.
Conclusions
CLIP has unlocked numerous new possibilities by bridging different modalities, a growing trend in both industry applications and research. What stands out is the simplicity and effectiveness of the approach.
At the same time its limitations, such as difficulties with fine-grained understanding and biases inherited from web data, highlight some areas for improvement. Fortunately, the open-source community has tackled some of these by reproducing the approach and training at a completely different scale in the OpenCLIP project [5]. Thanks for reading this far, see you! 🪿
References
[1] Learning Transferable Visual Models From Natural Language Supervision
[2] Deep Residual Learning for Image Recognition
[3] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale