
35. Segment Anything Model (SAM)
Cut out any object, in any image, with just a few clicks


Introduction
Image segmentation is the task of identifying exactly which pixels belong to an object or a class, possibly for every pixel in an image. If we go back just a few years, building such segmentation datasets was a very slow and labor-intensive process.
A good example is the Cityscapes [1] dataset from 2016, composed of thousands of urban street scenes for autonomous driving, each labeled with pixel-perfect masks for pedestrians, cars, traffic signs, and so on. Annotation and quality control took a mind-blowing 1.5 hours per image on average!
Fortunately, the prayers of annotators were answered in 2023, when Meta released Segment Anything (SAM) [2], the first foundation model of its kind that redefines how segmentation can be done at scale with just a few clicks.
A promptable segmentation machine
Traditionally, segmentation models were trained for a specific dataset or task and often required retraining when the domain changed, as inference was limited to a closed set of object categories (e.g., car, bike, or person).
SAM flips the script and follows the same paradigm of large language models: train once on an enormous dataset, and segment any object in any image with no further training. All it needs is to be prompted by the user via point clicks, bounding boxes, or potentially even text (not released). In practice, SAM is a promptable segmentation machine, giving full control to the user.
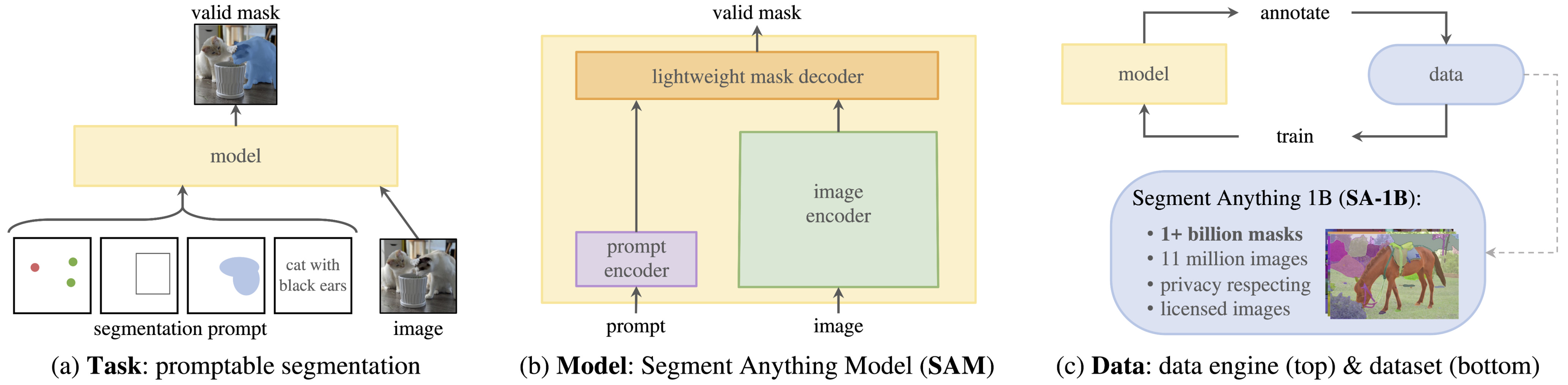
The scale of the data is unprecedented: SAM was trained on a dataset containing over 1.1 billion masks across 11 million images, the largest segmentation dataset ever built. Not surprisingly, the model itself was used to accelerate its own dataset creation, starting from a small human-labeled subset and iterating over its previous versions! More on this later, but now let’s check out the model architecture.
Segment Anything architecture
Standard segmentation networks typically follow a monolithic design, where an image goes in and a segmentation mask comes out, with no user interaction at any stage. This design applies to both CNN- and transformer-based architectures, and was the dominant paradigm in AI until the advent of LLMs.

SAM approaches the task differently, decomposing the model into three distinct components:
Image encoder. A vision transformer processes the image only once into a latent embedding, which can then serve multiple inference calls on the same image. SAM initializes the encoder from a pre-trained masked autoencoder (MAE) backbone, minimally adapted to 1024×1024 inputs by alternating local windowed attention with periodic global attention to handle the larger number of patches.
Prompt encoder. This turns user inputs in the form of points, boxes, and masks into something the model can process. In particular, each point or box corner is mapped to a positional embedding, which is then combined with a learned embedding that specifies the input type (point, top-left box corner, bottom-right box corner). Mask inputs, typically to refine or extend, are embedded using convolutions and summed element-wise with the image embedding.
Mask decoder. This part merges image and prompt embeddings to produce a segmentation mask, employing modified transformer decoder blocks, in which prompt and image embeddings interact bidirectionally via cross-attention layers. After that, we upsample the image embeddings and predict for each spatial location the probability of belonging to the mask specified by the prompt.
This promptable design makes SAM interactive and adaptable, therefore particularly suitable for annotation platforms, for example. Overall, the architecture is not too complex, but there is a big elephant in the room: large-scale data and where to find it.
A model generating its own data!
As we mentioned at the beginning, SAM is trained on 11M images and corresponding 1.1B segmentation masks, which makes it a foundation model for vision, serving many inferences on new images without task-specific retraining.
However, segmentation masks are not abundant on the internet. So, the team came up with a data engine that eventually culminates in a model annotating its own data. This happens through three stages:
Model-assisted manual annotation stage. At the start of this stage, SAM was trained using common public segmentation datasets. Then, this early version of the model assisted human annotators, tasked to freely annotate any object they wanted in images, and just refine the mask. With more data coming, the model was also retrained, decreasing the average annotation time for humans. In total, this annotate and retrain cycle occurred 6 times, and generated 4.3M masks.
Semi-automatic stage. At this stage, the selection was guided by the model confidence, ensuring that annotators focused on improving uncertain regions and increasing the diversity of collected masks. During this stage, an additional 5.9M masks were collected, and the model was retrained 5 times in the process. This phase is all about training on the most relevant data for the current model, which is the set of unconfident predictions.
Fully automatic stage. Eventually, the model generates masks without any annotator input. Specifically, the model is prompted with a regular grid of points, and we get a set of masks that may correspond to those inputs. Only confident and stable masks are selected, and to enhance the ability to segment small objects, multiple overlapping zoomed-in image crops are also processed. This was done for all 11M images in the dataset, producing a total of 1.1B diverse masks.
The final model is then trained only on the data generated in the fully automatic stage, and the scale and diversity of that dataset are all it needs to make a strong foundation model! This also enables zero-shot performance on domains and categories it hasn’t seen during training.

Conclusions
We looked at Segment Anything, the first foundation model for segmentation by Meta AI, upgrading image segmentation from a specialized task to a universal one.
Trained on a very large dataset and with a promptable design through points and boxes, SAM makes custom annotation tasks orders of magnitude faster. On top of that, it also provides a building block for fully automated text-to-segmentation systems such as Grounded SAM [3].
This model was part of the first generation of open-source vision models by Meta, accelerating both research and applications across the community. Very recently, we also saw another big announcement from them with DINOv3! If you want a quick refresher of the DINO architecture, feel free to check out this old post. Thanks for reading this far, and as always, see you next week!

References
[1] The Cityscapes Dataset for Semantic Urban Scene Understanding
[2] Segment Anything
[3] Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks