
50. VoRA: Vision as LoRA
Giving visual capabilities to LLMs without external encoders

Introduction
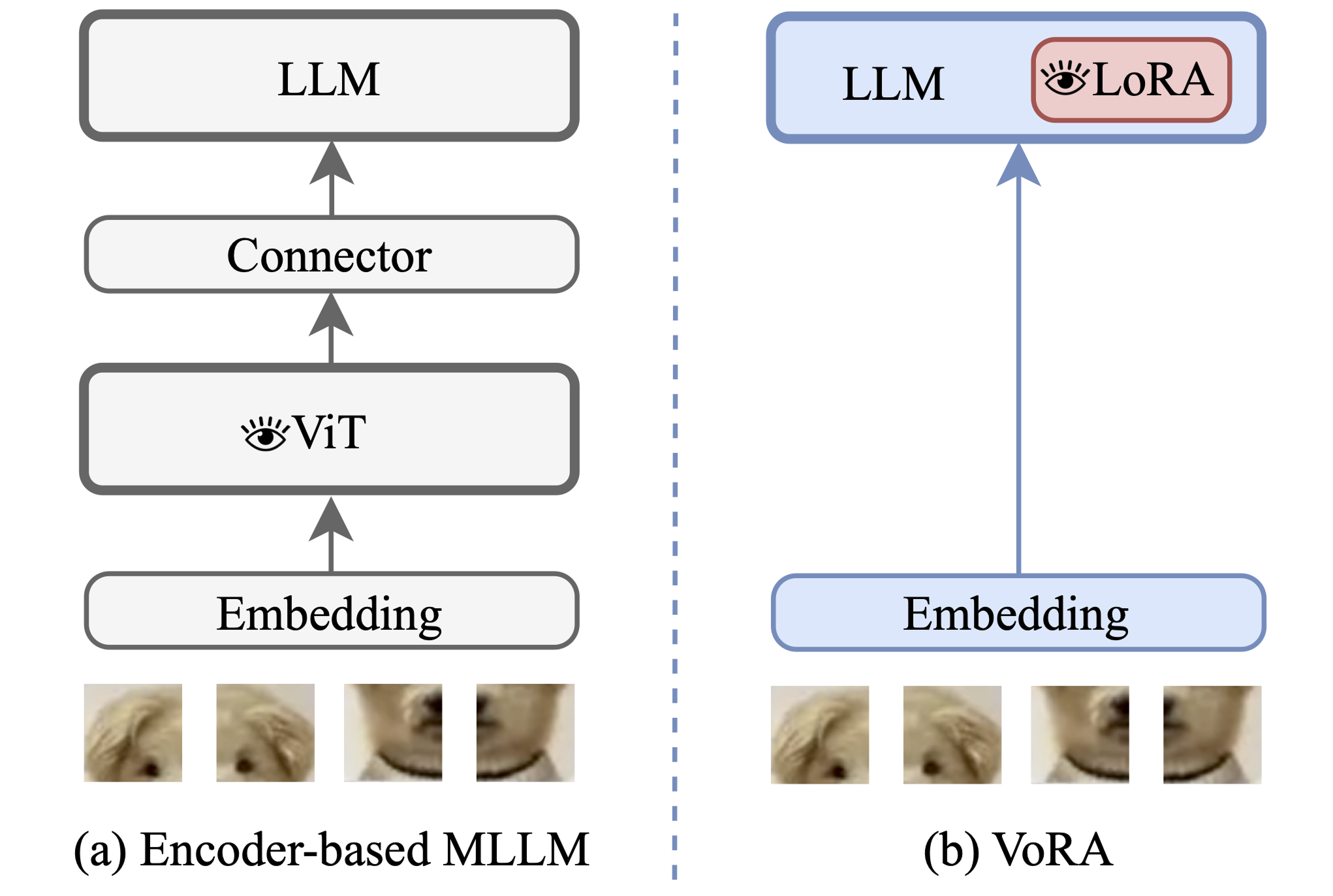
Today, multimodal capabilities are consolidated in language models, with plenty of frontier ones possessing the ability to understand visual information alongside text. The classic recipe to unlock this is to use a separate vision transformer encoder and a projector to align image patch features to the same latent space text uses, treating those as regular tokens. LLaVA, which we covered in a previous post, is the most famous example of this design.

Vision as LoRA (VoRA) [1] by ByteDance is another way of achieving multimodality, baking the visual capabilities directly into the language model weights. Let’s see how this is done, and which recent techniques it blends.
Internalizing vision with LoRA
The core idea here is to replace the heavy external vision encoder with lightweight adapters inside the language model. These modules learn to process exactly the same input that would be fed to the ViT encoder, i.e., raw image patches after a simple (trainable) linear projection with positional embeddings.
More specifically, the researchers insert LoRA [2] layers into the first several blocks of a frozen LLM (not all of them), targeting the linear projections within the attention and the feed-forward MLPs. Editing all those layers results in a deeper adaptation compared to what we would normally do, but it’s nothing out of the ordinary (in fact, check out this blog post from Thinking Machines Lab [3] on how to train with LoRA).
Authors report that relatively high-rank LoRA matrices, such as rank 1024, are key to success for their 7B Qwen2.5-Instruct model, and that not using LoRA would make training explode and incur catastrophic forgetting.
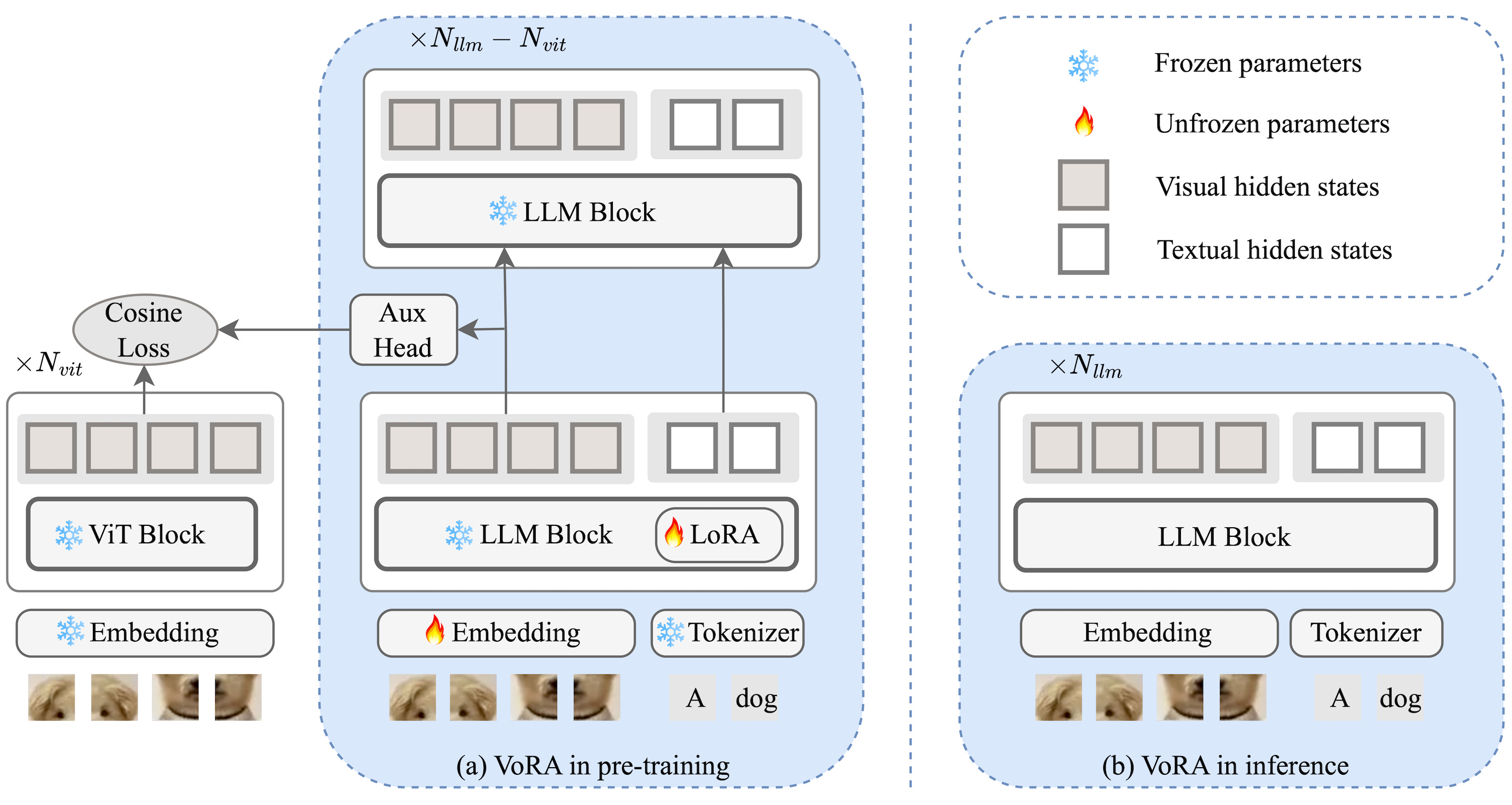
If you remember how LoRA variants work under the hood, you’ll recall that it is indeed a reasonable way to go here because it comes with parameter efficiency by training only “small” matrices, ensures the preservation of language knowledge by keeping base weights frozen, and enables weight merging after training without added inference latency. If you don’t, there is also an article on that :)

Block-wise distillation
The second ingredient in the VoRA recipe is block-wise distillation from a pre-trained vision transformer. What’s the idea here? Basically, learning high-end vision from scratch is a data-intensive process that requires billions of images. Also, already existing models are smart, so why not reuse them?
To improve training efficiency, VoRA utilizes a teacher-student framework where a pre-trained Vision Transformer acts as the teacher (in this case, the vision encoder is AIMv2-Huge-448p from Apple [4]). This provides a rich source of visual priors already aligned with language, since it is a multimodal LLM on its own.
The idea is the following: if the ViT encoder has N blocks, for each block i in the first N layers of the LLM, its hidden states are aligned with those of block i in the ViT. LLMs are often deeper than vision encoders, so this method translates to adapting the early stages of processing.
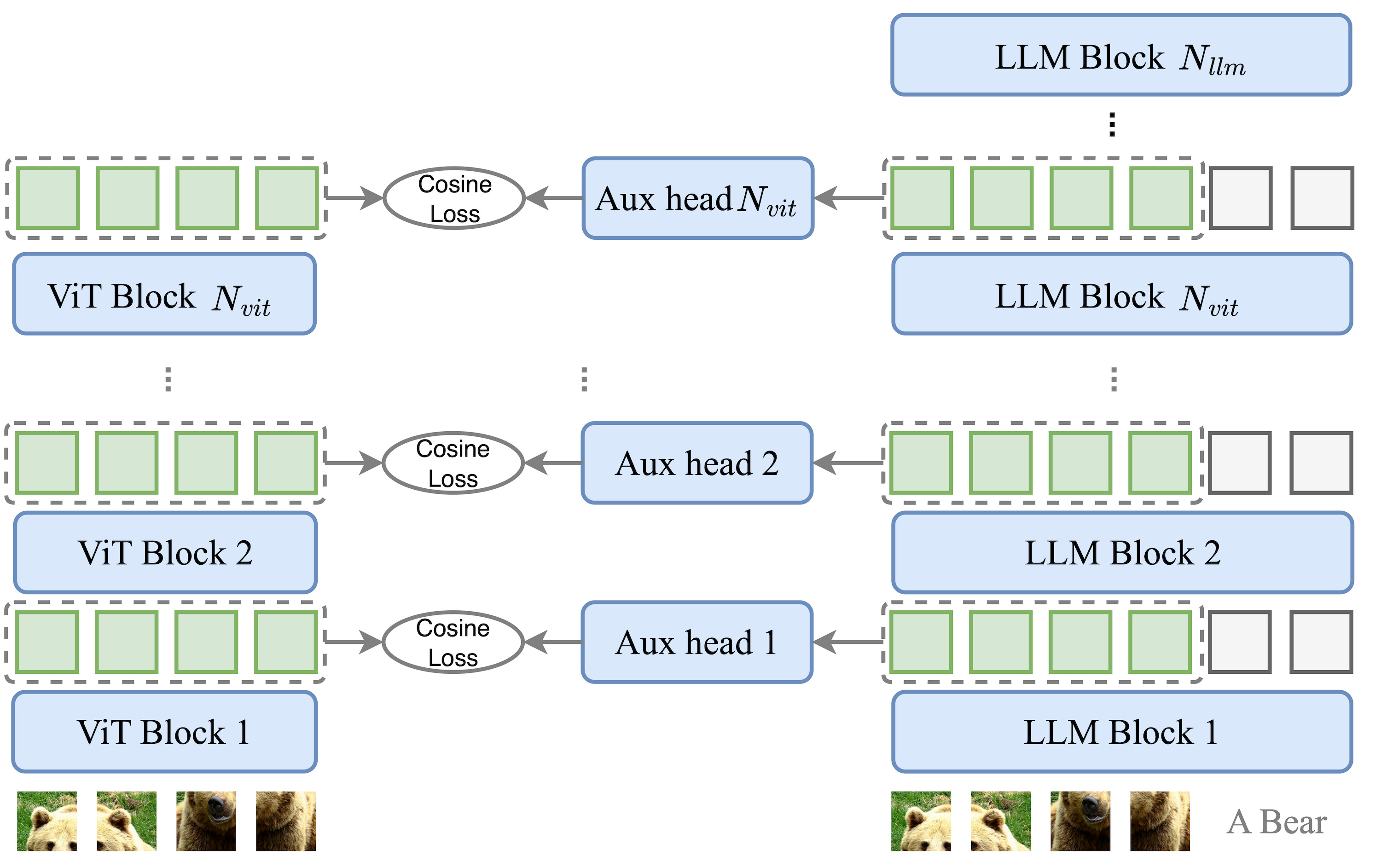
The distillation loss uses cosine similarity to maximize the agreement between the projected LLM features and the ViT embeddings. Specifically, this happens through a lightweight auxiliary head consisting of normalization and a linear layer that matches the LLM hidden states to the teacher’s embedding size. By combining this distillation objective with the standard language modeling loss, the model learns visual features much faster than through standard training alone.
Bi-directional attention for images
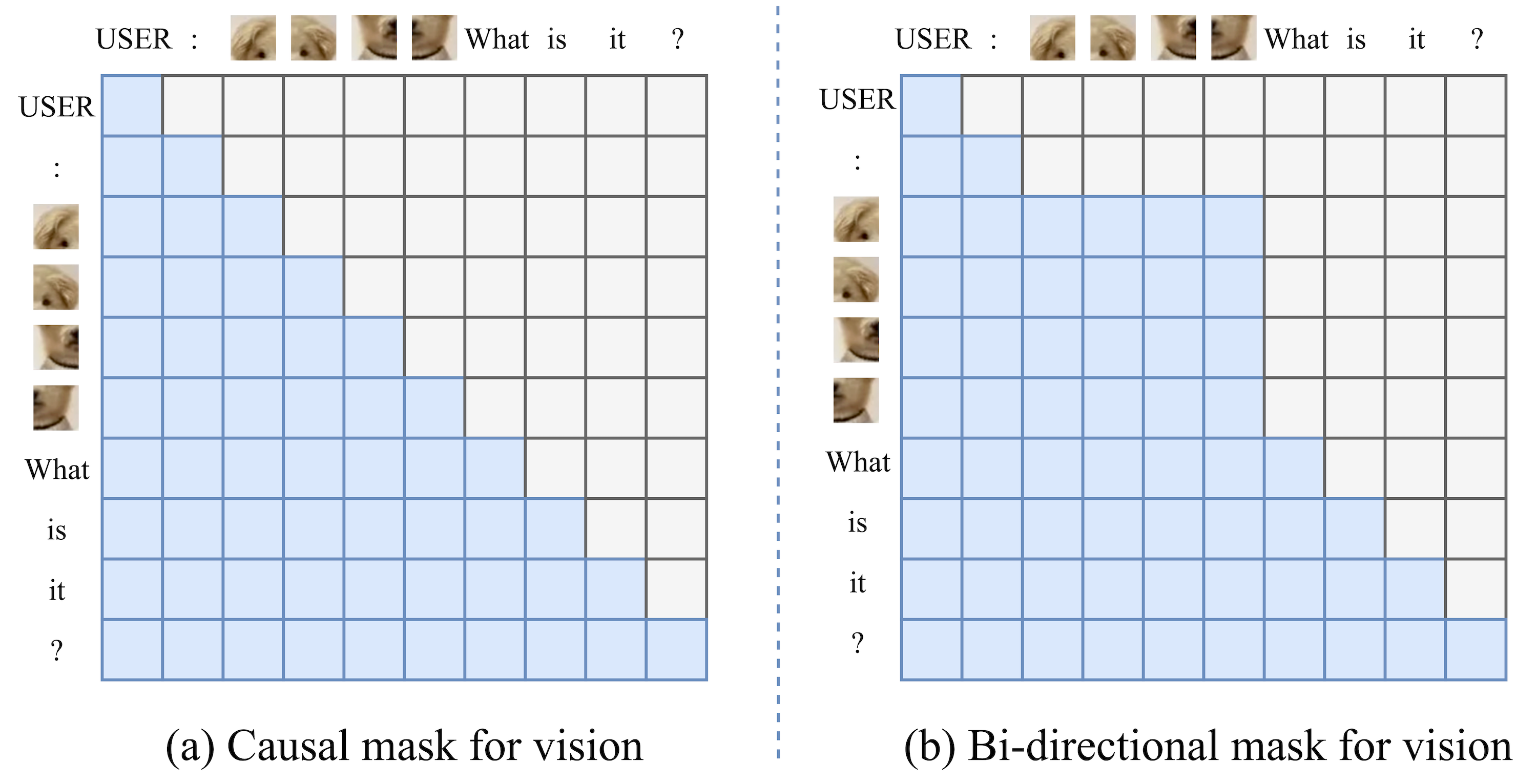
The third and final ingredient is changing the attention mask. Standard decoder-only language models are causal, meaning tokens can only look at the words that came before them. On the other hand, spatial relationships are naturally bi-directional, meaning all image patches in a standard vision encoder can see all other image patches in each attention computation.
Since we now pass images as input alongside text, we have to fuse these two concepts. VoRA addresses this by replacing the causal mask with a bi-directional attention mask for all visual tokens. This allows every image patch to still attend to every other patch simultaneously, while keeping the autoregressive nature of text intact.
The new attention pattern looks like this, and ablations report how implementing this change leads to significant performance gains on visual benchmarks.
VoRA vs LLaVA/MLLMs
As we just saw, compared to traditional LLaVA-like or even more modern multimodal LLMs, VoRA removes the external dependency for a vision encoder during inference. This also comes with a side benefit, which is the ability to handle images of arbitrary resolutions. If an image produces more or fewer tokens, that is completely fine, as the LLM inherently has learned to handle variable-length sequences. This contrasts with standard VLMs, which often crop and/or resize to match the encoder requirements.
On the other hand, the clearest limitation of VoRA is the requirement for additional pre-training data to compensate for the absence of an external vision model, because the LLM has to learn visual feature extraction from scratch. Distillation accelerates this process and provides the benefit of not adding parameters during inference, but this training phase is certainly more expensive than attaching a pre-trained ViT and training the connector.
Speaking of the connector, another downside is that VoRA does not yet implement image token compression. This lack of compression means that very high-resolution images can substantially increase the context window. This is also true for LLaVA, but it is not true for modern MLLMs, where the connector of image/video inputs utilizes specialized layers to shrink the visual sequence by at least a factor of four.
Conclusions
VoRA shows that turning an LLM into a multimodal one can be successfully achieved through low-rank adapters, hinting at the fact that this kind of intelligence might emerge from internal reorganization of concepts already existing. It would not be crazy to see this adaptation also for modalities like audio or 3D point clouds.
This block-wise distillation is also a fairly general method, and it’s becoming more and more popular among VAEs and generative models, too. I’m covering this soon: it’s a very exciting topic with remarkable speedups! Thanks for reading, and see you in the next one!
References
[1] Vision as LoRA
[2] LoRA: Low-Rank Adaptation of Large Language Models
[4] Multimodal Autoregressive Pre-training of Large Vision Encoders