
58. Utonia
Toward one encoder for all point clouds


Introduction
In a previous post (#46), we covered Sonata [2] and Concerto [3], two strong 3D point cloud encoders trained with self-supervised learning.
Sonata is essentially DINO for 3D: a student sees local and masked crops of a point cloud and is trained to match the representations of the teacher processing a global, unmasked view. Concerto extends this by simultaneously distilling knowledge from a frozen image encoder via renders, baking 2D semantics into the 3D backbone.
Both were a big step forward, showing that powerful 3D representations can emerge without a single label within individual domains. But in the same way image and video encoders are considered universal at this point and can be applied to a wide range of settings, we ideally want a single 3D encoder that handles indoor, outdoor, and object-centric point clouds all at once. That is exactly what Utonia [1], from the same research group, tries to achieve.
The problem with joint training
The obvious first attempt is to merge all available datasets and train one encoder jointly with the latest Concerto recipe. As it turns out, this doesn’t work well: naively merging domains causes large performance drops across the board compared to domain-specific models. The authors identify three root causes:
Granularity shifts. Point clouds across domains live at completely different spatial scales and resolutions. What counts as a meaningful local region indoors is noise-level detail in an outdoor LiDAR scan, and vice versa. Features end up tightly coupled to domain-specific scale, making it impossible to share general geometric patterns.
Gravity convention bias. Scene-level data is almost always gravity-aligned, and many semantics depend on it. Single object models, on the other hand, appear in arbitrary orientations. Height becomes a domain-identifying cue, and the model learns to use it to separate domains rather than learning transferable geometry. As seen in the PCA of Sonata and Concerto features, height overrides semantics when an object does not follow the canonical upright orientation, and the features are not consistent under 3D transformations.

Scene-level models inherit a strong gravity prior, making features vary with height even on a single object. Utonia breaks this by applying full 3D rotations to object data during training. From [1]. Inconsistent modality availability. Some point clouds have colors and normals, others don’t. The model exploits the richest available channels whenever it can, creating a fragile dependency that breaks dramatically when those modalities are missing or defined differently at test time. In some sense, modality statistics again become domain-identifying cues.
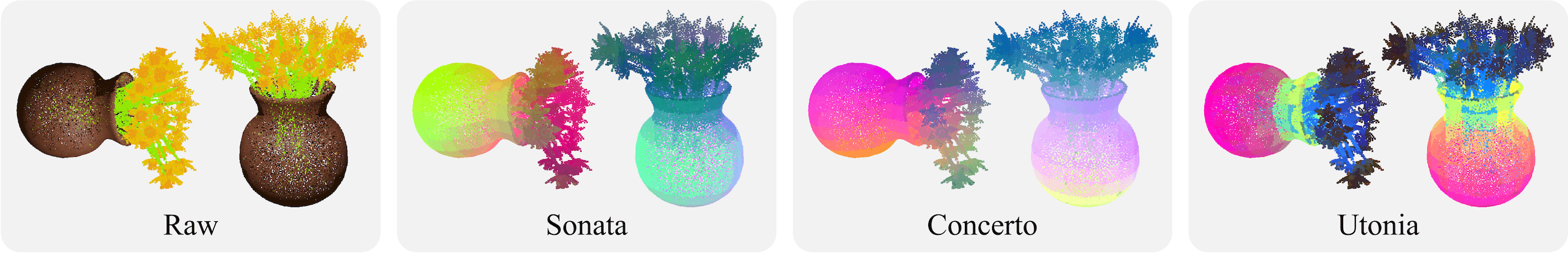
Method
Utonia manages to pretrain a single Point Transformer V3 encoder [4] across all domains at once: indoor scans, outdoor LiDAR, remote sensing, object CAD models, and video-lifted point clouds. For a bit more information about the architecture, check out my previous post on Concerto.

In short, PTv3 serializes point clouds into 1D sequences using several space-filling curves, groups nearby points into local patches, and applies windowed attention within each patch. Information exchange happens by shuffling the serialization pattern across layers, so points that were in different patches in one layer end up neighbors in the next.
Three targeted changes to the Concerto recipe are all it takes to make joint training work, none of which require domain-specific modules:
Perceptual granularity rescale. The granularity and gravity problems are addressed together. The intuition comes from how humans perceive: we operate at a roughly fixed angular resolution, so a toy car up close and a real car far away look structurally similar despite the scale difference. Thus, every point cloud is divided by its domain’s natural scale before processing, so that one unit roughly means the same thing (e.g., the size of a car tyre). This scale is empirically predefined per dataset and jittered during training to avoid overfitting. On top of this, scene datasets get only augmentations that preserve upright structure, while object datasets receive arbitrary 3D rotations. This way, the model learns that gravity alignment is a scene-level concept, not a universal one.
RoPE on granularity-aligned coordinates. Rescaling aligns the spatial unit, but the model still needs a way to reason about relative point positions that works across different densities and domains. The fix is to apply Rotary Position Embedding in every attention layer. 3D RoPE encodes relative geometry continuously and without any extra parameters, making the model less sensitive to sampling-induced biases. Following DINOv3, RoPE jittering is also used.
Causal modality blinding. Point clouds across domains don’t share standardized input forms: some have colors and/or normals, others only coordinates. The solution is first to define a unified interface by concatenating all three and filling missing channels with zeros, and then to randomly drop color and normals during training. This can be done at two levels: dropping entire modality groups for a full sample or masking individual points. With this input dropout, the model learns to work without over-relying on the additional modalities, while still benefiting from them when they are present.
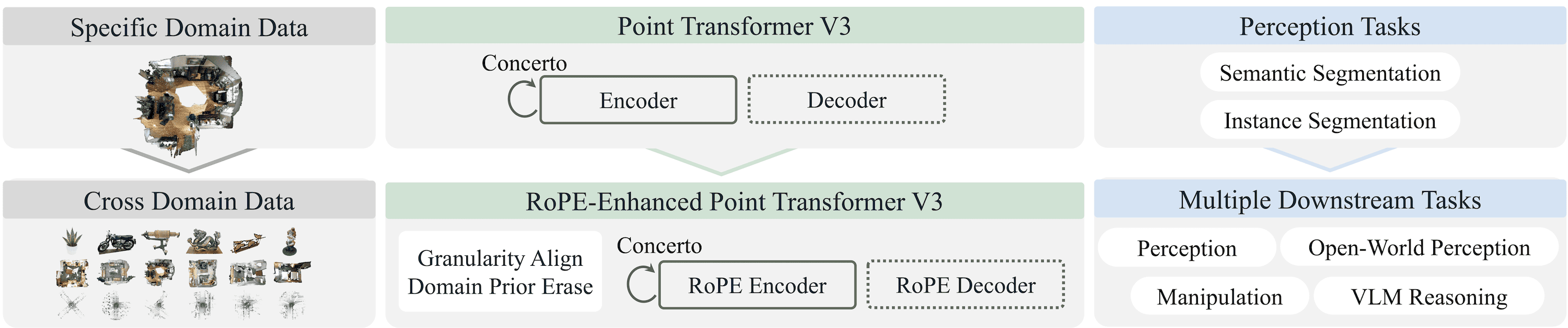
Architecture-wise, the only change compared to Concerto is the aforementioned addition of RoPE into PTv3. The model is also slightly scaled up to 137M parameters, partly to accommodate RoPE’s requirement for channel dimensions divisible by 6, and partly because the ablations confirm that this extra capacity is needed for multi-domain training to consistently beat domain-specific baselines. 2D image supervision in the 2D-3D SSL is still provided by DINOv2 with registers, so lots of room for improvement there if this were to be swapped!
On the data side, the scale increase is instead dramatic: Concerto trains on around 40k point clouds, while Utonia trains on 250k cross-domain point clouds plus 1M sampled object assets from Cap3D [5], a large collection from the web. Training follows a two-stage schedule, starting with four high-quality datasets for a stable initialization before continuing on the full mixture. The result is the most powerful 3D checkpoint the world has ever seen, working across all domains!

Conclusions
Utonia is a really great step forward for 3D understanding! There is one result in the paper that catches the eye more than everything else, and it is not to be found in benchmark numbers. When querying the trunk of a toy car from a CAD model and retrieving the most similar region in an outdoor LiDAR scan, Concerto completely fails to match it to a real car, but Utonia retrieves it correctly. This emerges in the same way cross-domain semantic similarity emerges in DINO features, and means strong generalization across the 3D world.

Beyond that, Utonia features improve any downstream task, ranging from 3D part segmentation, open-vocabulary scene understanding, spatial reasoning in video-language models, and robotic manipulation. For example, its ability to separate objects from supporting surfaces and remain coherent under occlusion and partial observations makes it great for grasping and motion planning. It’s basically like swapping the image or video encoder to the latest ones in every computer vision application: you see a nice jump :)
From here, the paper explicitly mentions that next-generation backbones should extend to 4D spatiotemporal pretraining, handling dynamic scenes and making motion and temporal consistency truly part of the representation. Exciting stuff ahead for the perception and robotics world! Thanks for reading, and see you in the next one.
References
[1] Utonia: Toward One Encoder for All Point Clouds
[2] Sonata: Self-Supervised Learning of Reliable Point Representations
[3] Concerto: Joint 2D-3D Self-Supervised Learning Emerges Spatial Representations