
54. From SAM to SAM 3
Evolution of promptable image and video segmentation


Introduction
The evolution of segmentation models in the last few years has been very exciting. Beyond the performance gains from architectural improvements like DPT (#21) and swapping convolutional backbones for transformers, the field has undergone a fundamental paradigm shift. In particular, we transitioned from training specialist models for predefined, closed sets of classes to using universal open-vocabulary foundation models that can handle semantic concepts across images and videos.
The Segment Anything Model (SAM) family by Meta AI has been the main driver of this evolution, pioneering the idea of promptable segmentation. Over three releases, it grew from a click-based annotation tool to a video tracker, and eventually to a system that understands language and image exemplars natively. That is quite a journey for a tool originally designed to assist with annotations!
In this long post, we will retrace the full evolution of this family, reviewing the architectural decisions and data engine at the base of SAM, then jumping into the temporal extension of SAM 2, and finally the semantic reasoning of the newly released SAM 3. Enjoy this transition from space to time to concepts!
NOTE: This post may appear clipped or truncated in the email, as it is quite long. If so, please head over to Substack to read it fully.
Recap of SAM: the spatial foundation
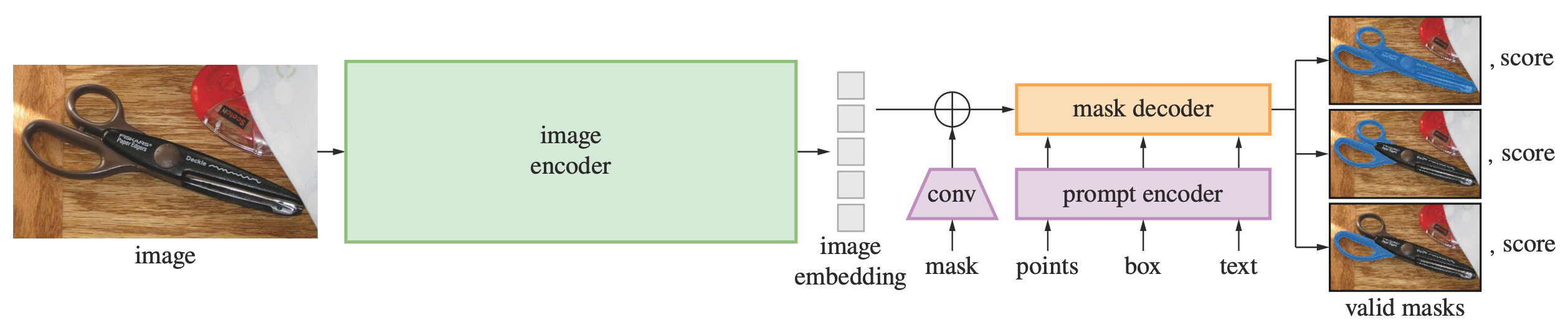
Released in April 2023, the original SAM [1] represented a complete flip of the classical problem statement in segmentation. Rather than training a model to recognize a fixed set of predefined classes, SAM is trained to segment whatever the user points at, expressed via clicks, bounding boxes, or coarse masks.

A key design insight is how it splits computation into two parts: a heavy image encoder that runs once per image and caches its output, and a lightweight prompt encoder and mask decoder that can respond to new prompts in real time.

If you want the full technical breakdown, I covered it already in depth in the article linked above. But for the purposes of this piece, here is a quick recap of the key architectural components before we move on:
Image encoder. The backbone is a ViT-H (636M params) adapted for high-resolution inputs via windowed (local) attention in most blocks, interleaved with a smaller number of global attention blocks. This MAE-pretrained encoder (#24) represents the heavy computation, running just once per image and then operating off the cache.
Prompt encoder. This tells the model what specific object to segment. It handles sparse inputs (points, boxes) and dense inputs (masks). Points and boxes are represented using positional encodings summed with learned embeddings for each prompt type (e.g., “point”, “top-left corner”, or “bottom-right corner”), while mask prompts are embedded using convolutions and summed element-wise with the patch embeddings. Encoding the prompt is lightweight, so it can be injected and processed in real-time.
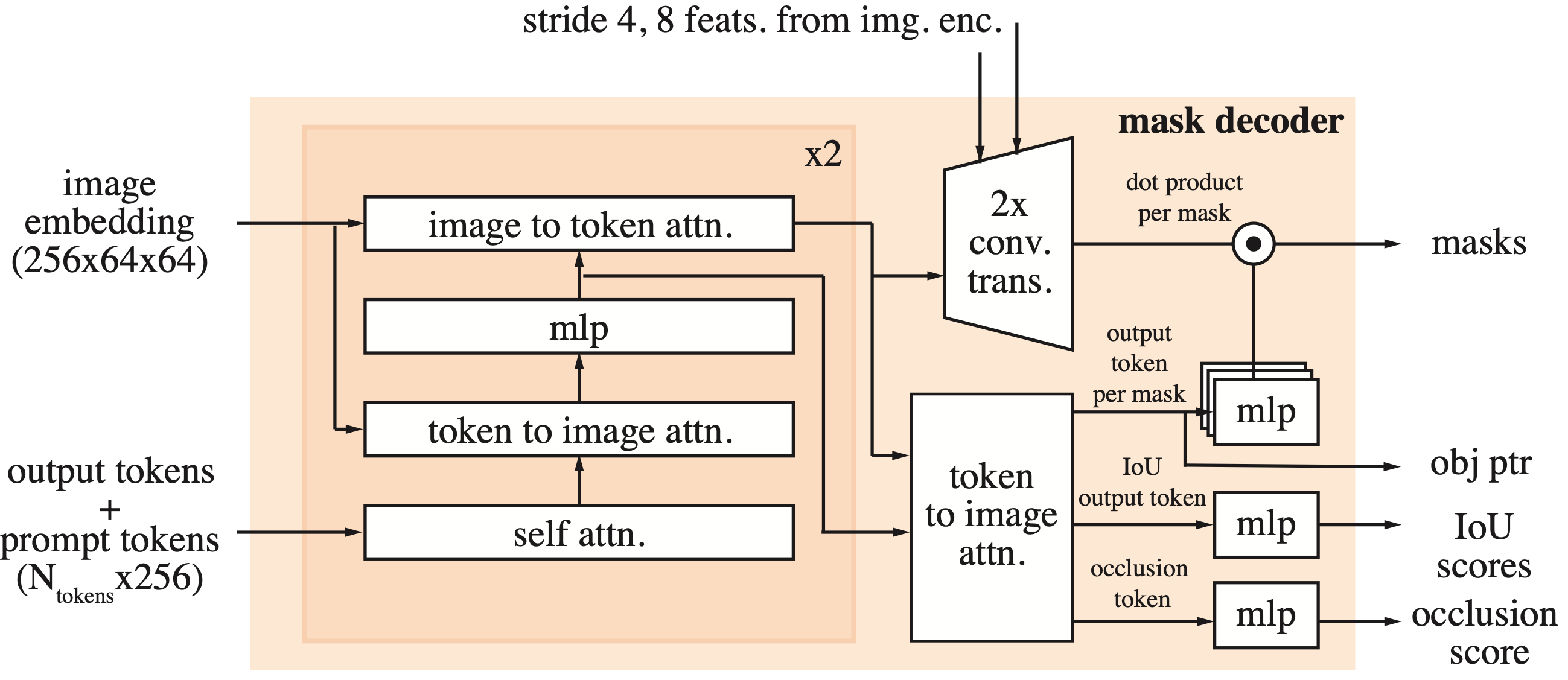
Mask decoder. Once the image and prompts are encoded, the mask decoder generates the final output. It uses modified transformer decoder blocks where prompt and image embeddings interact bidirectionally via cross-attention layers. Finally, the image embeddings are upsampled, and for each spatial location, we evaluate the probability of it belonging to the mask specified by the prompt. To handle prompt ambiguity, the decoder always produces three candidate masks at different levels of granularity, each with a confidence score.
As for the data engine, it is the key to the generalization capabilities of SAM. The authors constructed the dataset through three distinct phases, two of which relied on a human-in-the-loop approach:
In the initial assisted-manual stage, annotators focused on hard active learning samples and corrected errors to retrain the model a total of six times, scaling the encoder from ViT-B to ViT-H along the way.
This evolved into a semi-automatic stage where humans only labeled objects the model missed, leading to five additional rounds of retraining.
The pipeline concluded with a fully automatic stage that produced SA-1B: a massive dataset of 11 million images and 1.1 billion masks, on which the final version of the model was trained.
Despite its remarkable generalization, the first version of SAM felt primarily like a tool designed to assist annotators. In practice, its use often required significant manual intervention, with users having to supply negative prompts to correct errors or multiple positive prompts to fix incomplete masks. Furthermore, it missed two critical capabilities:
On one side, it lacked an extension to video, so it had flickering results if applied to a sequence of frames.
On the other hand, text prompting was missing. While a text interface via CLIP was demonstrated in the paper and shown in all figures, the weights were never released, leaving this crucial capability out…
These limitations were addressed by SAM 2 and Grounded SAM, respectively. While SAM 2 unified image and video segmentation to solve the temporal aspect, Grounded SAM integrated open-set detection as a prompt to unlock a first form of text-prompting capability that would later be the core of SAM 3. Let’s continue!
SAM 2: the temporal extension
Static images are only part of the problem, as real-world applications often require annotations on videos where objects move, get occluded by obstacles, and the camera angle changes. All of these factors essentially scream for good tracking.
Applying SAM frame-by-frame to annotate these videos is possible, but is extremely inefficient compared to the ideal lower bound of annotating just one frame. Furthermore, this approach lacks object permanence, treating the same subject in distinct frames as completely unrelated entities. Released in August 2024, SAM 2 was designed to solve these issues, unifying image and video through a new task: promptable visual segmentation (PVS) [2].
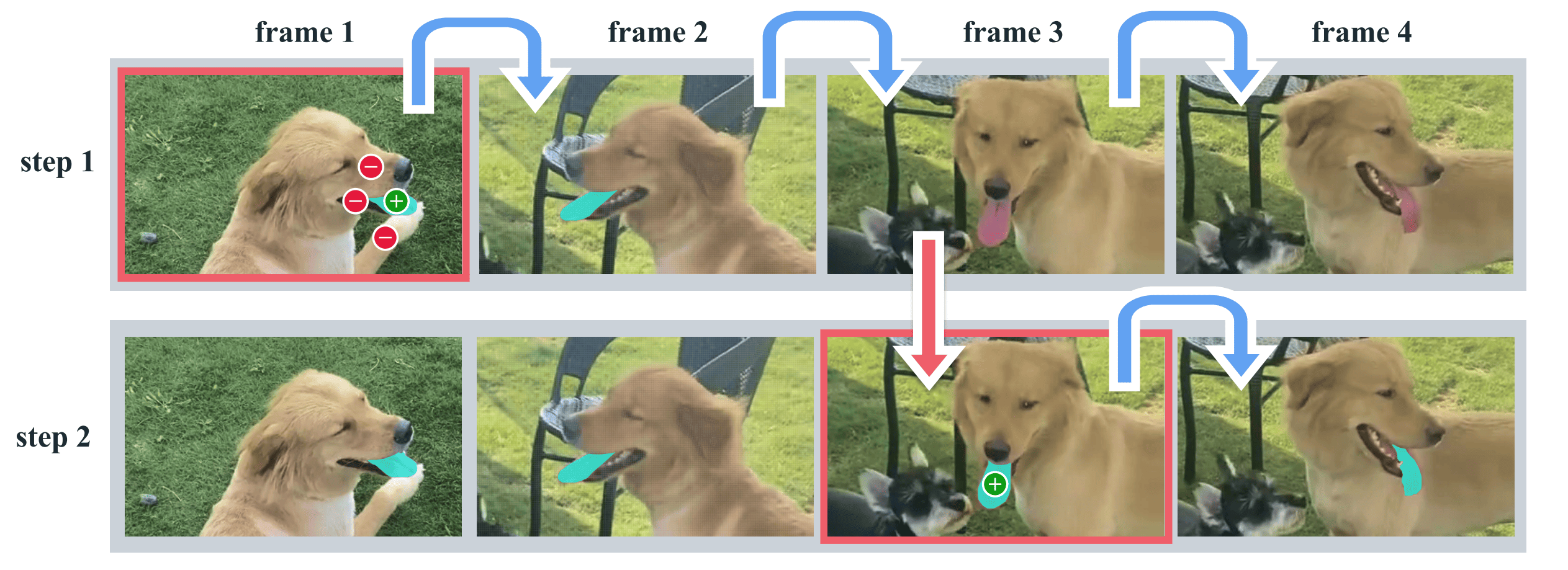
This task allows users to provide prompts on any frame of a video, and after mask propagation, additional prompts can be added in any other frame to refine (see above). The output is called a masklet, i.e., the spatiotemporal extension of a mask, meaning a per-object binary mask track that spans all video frames rather than a single image.
Beyond video, the new model is also a major upgrade for single images: it is more accurate than the original SAM and 6× faster, thanks to a redesigned image encoder.
From ViT to Hiera
Speed is a major concern for SAM 2 due to the hard requirement of processing high-resolution videos at many frames per second. For this reason, the backbone was switched to Hiera, a Hierarchical Vision Transformer [4]. The new encoder is also pretrained with a MAE objective (#24), so no changes there.
While a standard ViT maintains a fixed token length throughout the network, Hiera does not and progressively reduces the patch count using max pooling operations over 2×2 groups. In other words, Hiera moves away from the isotropic design of standard ViTs and adopts the pyramidal structure of a ConvNet.
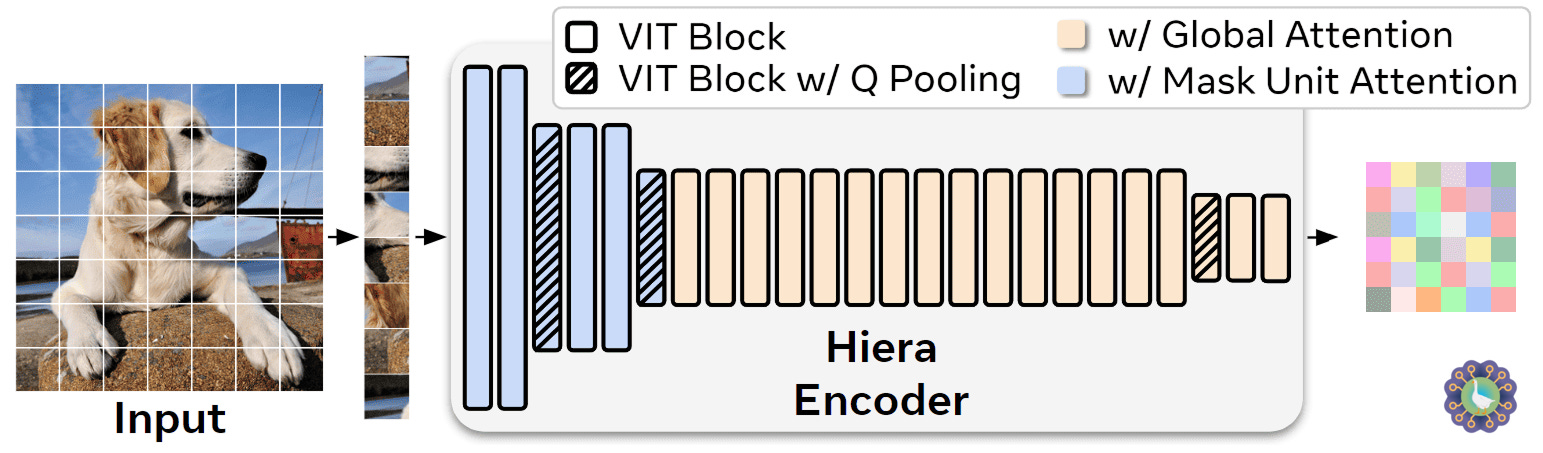
This model is faster than ViT for any given input size, and part of the trick is applying local attention (blue) in the early blocks, where there are more patches, and global attention (yellow) in the later ones, where the token count drops due to pooling. Such a choice also allows the model to process high-resolution images efficiently. However, a consequence is that the output feature maps are significantly smaller than before.
To counter that, the SAM 2 encoder combines different levels of the feature pyramid (last two stages) to produce the final image representation. Meanwhile, the mask decoder also adds features from the first two Hiera blocks to recover high-resolution details needed for precise segmentation (similar to what a U-Net does), bypassing the memory attention below.
The memory mechanism
The critical innovation in SAM 2 is the memory bank, which conditions the model on past predictions and prompted frames. The mechanism works in two modes: in offline mode, where the full video is available upfront, the memory bank can utilize information from both past and future prompted frames relative to the current one; in streaming mode, memory flows strictly forward in time, and new prompts can be provided on low-confidence frames to keep the masklet on track.
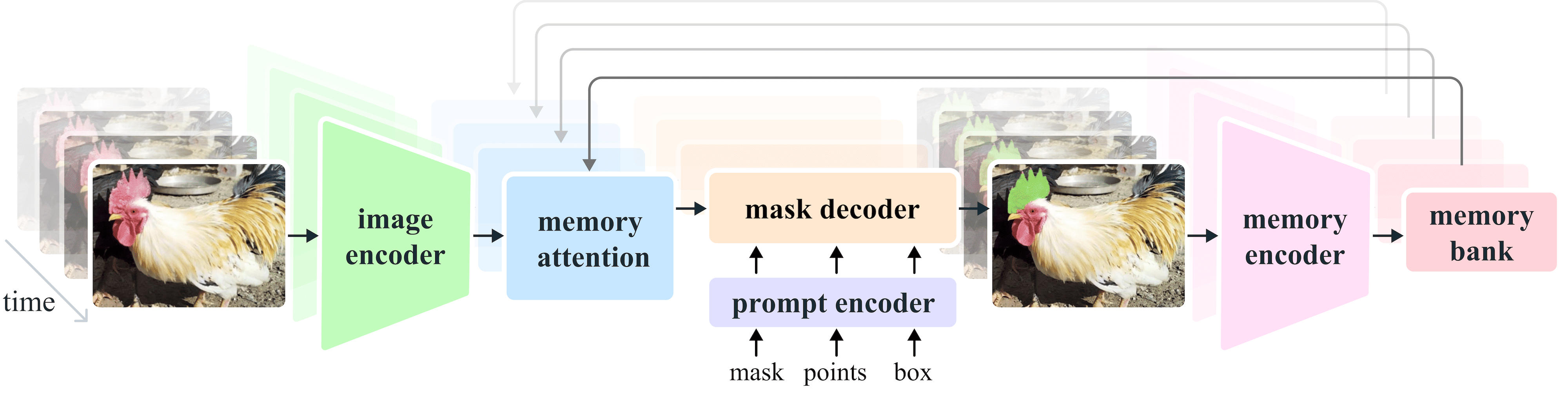
The overall memory mechanism is composed of three parts:
Memory encoder. As the mask decoder processes a frame, it downsamples the mask prediction using a convolutional module and sums it with the unconditioned frame embedding from the image encoder. Lightweight convolutional layers fuse the information right after, and this serves as the representation of a frame.
Memory bank. This is a FIFO (First-In-First-Out) queue that stores memories up to N recent unprompted frames and M prompted ones. Both sets of memories are stored as spatial feature maps. To capture semantic information, the queue also stores a list of tokens derived from the mask decoder’s output. Essentially, this bank stores downsampled masks alongside some embedding of the tracked object.
Memory attention. The final piece is the memory attention, which acts as the bridge between the memory bank and the current frame. Positioned after the Hiera encoder, it consists of a stack of L transformer blocks, the first one taking the image encoding from the current frame as input. The blocks repeat vanilla self-attention, cross-attention to the memory bank (both spatial features and object pointers), and finally an MLP.
The rest of the architecture mostly mirrors the original SAM, with the decoder capable of outputting multiple target masks for each frame. Since no valid object might exist in some frames due to occlusion, an additional head in the decoder predicts whether the object of interest is present in the current frame.
SA-V dataset
Consistent with the strategy used for the original SAM, the authors put a lot of effort into data, adapting the engine specifically for the video domain. The resulting SA-V dataset consists of ~51,000 videos (54% indoor and 46% outdoor) and 643,000 masklets, providing the supervision needed to teach the model how objects deform and move over time.
The data engine follows the familiar multi-phase structure. However, with a model already available, manual labeling is replaced by a model-assisted approach where SAM generates the masks from the beginning. Here is a quick summary:
Phase 1: SAM per frame. Annotators label a target object in every frame of a video at 6 FPS, assisted by SAM and manual editing tools such as a “brush” and “eraser”. No tracking model is available yet to handle the temporal propagation of masks to other frames. This phase yields 16K masklets across 1.4K videos, and this approach is also used to annotate SA-V val and test sets.
Phase 2: SAM + SAM 2 Mask. This phase introduces a preliminary version of SAM 2 into the workflow, accepting only masks as prompts. The model is trained on phase 1 data and publicly available datasets, and updated twice as phase 2 data comes in. Annotators generate an initial mask using SAM and then use this SAM 2 to propagate it temporally to other frames. At any subsequent video frame, they can modify the predictions by re-annotating a frame mask from scratch and re-propagating. The final balance is 63.5K masklets.
Phase 3: SAM 2. In the final phase, the fully-featured SAM 2, which accepts all types of prompts, is used to annotate videos. Annotators only need to provide occasional refinement clicks in intermediate frames, as opposed to annotating from scratch. During phase 3, SAM 2 is retrained and updated five times, collecting 197.0K masklets. In parallel, 451.7K automatic masklets are generated by prompting with a regular grid of points in the first frame, with the goal of covering objects of varying sizes and positions in the background. These are then sent to verification.
If you recall that you should train a model mostly on its errors, you can appreciate how this interactive error refinement is what makes SAM 2 robust. The model is trained jointly on image and video data, first pretraining on SA-1B, and then on a mixture of SA-V, internal, and open-source data, plus a 10% subset of SA-1B. And that’s pretty much it for this one: video segmentation is solved to a good degree.
Grounded SAM: text-to-mask detour
Before we jump into SAM 3, another paper deserves a few words. The first SAM model was strictly geometric, and the text interface mentioned in the research was never released. This was unfortunate, as to automate segmentation annotation (e.g., “segment all the people”), a human was still needed to spatially prompt the model.
To fill this gap, the research community built Grounded SAM [5]. This pipeline evolved in parallel for a couple of years into Grounded SAM 2, until the arrival of SAM 3 finally bridged the semantic gap.

Marrying detection and segmentation
The idea of the Grounded SAM series is straightforward: if SAM needs a box to segment an object, and we have models that can generate boxes from text in an open-vocabulary fashion, why not chain them together?
The key component here is Grounding DINO [6], a zero-shot object detector that takes an image and a text prompt as inputs and outputs bounding boxes. Despite the shared name, this model is distinct from the self-supervised DINO image encoder and NOT based on it.
Without going too much into detail, this model works by fusing text embeddings from BERT with image features from the DINO detector [7] (a transformer-based detection architecture) deep in the network, allowing the detector to “ground” the concepts in specific spatial regions to their text description. Since text embeddings naturally live in a continuous semantic space, open-vocabulary detection is achieved as a byproduct.
The Grounded SAM pipeline looks something like this:
Input. An image and a text prompt (e.g., “segment all the horses”).
Detection (Grounding DINO). The detector processes the image and outputs bounding boxes for every subject, horses in this case.
Prompting. These boxes are fed into SAM as geometric box prompts, exactly like a human would do.
Segmentation. SAM takes the boxes as inputs and returns a precise mask for the object inside each box.
A Frankenstein solution
This worked surprisingly well for just concatenating two models, and suddenly, we had text-to-mask capabilities! However, from a research perspective, it was still a bit of a prototype. Notable limitations are:
Error propagation. If Grounding DINO drew an incorrect box, SAM would faithfully try to segment whatever was in that box. SAM trusts the prompt implicitly, so there is no guarantee that the text and segmentation result match.
Inefficiency. Grounding DINO processed the image with its own encoder to generate prompts. Then, SAM ran a completely different ViT on the same image to get the features for segmentation. This meant the heavy lifting of feature extraction happened twice.
Disconnected. The models didn’t talk to each other: SAM didn’t know how the box got there, and Grounding DINO didn’t know how to get more accurate. The only way to improve was by swapping components with newer ones.
And this actually happened. The second version of Grounded SAM did not introduce significant methodological changes but made use of better detectors and SAM 2. Anyway, this detour proved that the community desperately wanted promptable concept segmentation (PCS), the ability to ask for concepts in free-form text instead of coordinates. And this is what SAM 3 completely focuses on, with a redefined architecture that solves most of the problems above.
SAM 3: the semantic integration
While SAM 1 and 2 addressed the spatial and temporal axes of segmentation, the semantic understanding functionality provided by Grounded SAM was missing from the native architecture. Released in November 2025, SAM 3 by Meta finally bridges this gap natively, completing the final piece of the puzzle [3].
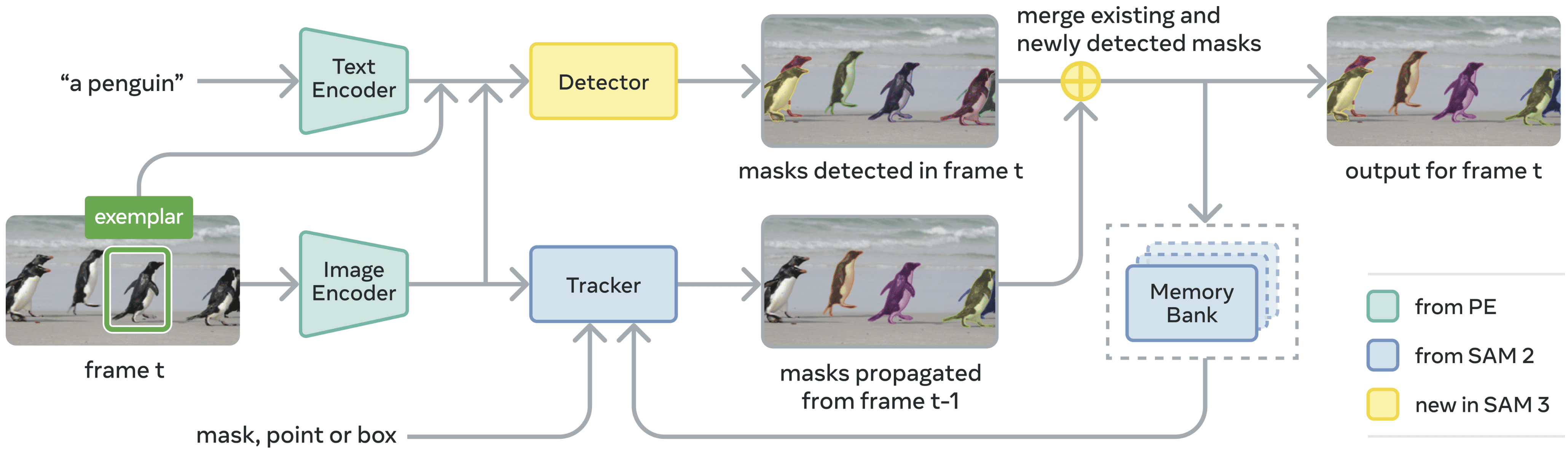
Switching to PCS fundamentally alters the everyday annotation workflow. Unlike previous versions that required users to point at a specific object, SAM 3 accepts text and/or positive/negative visual exemplars. Basically, we can now request a category and get a fully segmented video, or annotate a single instance via bbox to propagate that label to every other matching object in the video.

A unified architecture
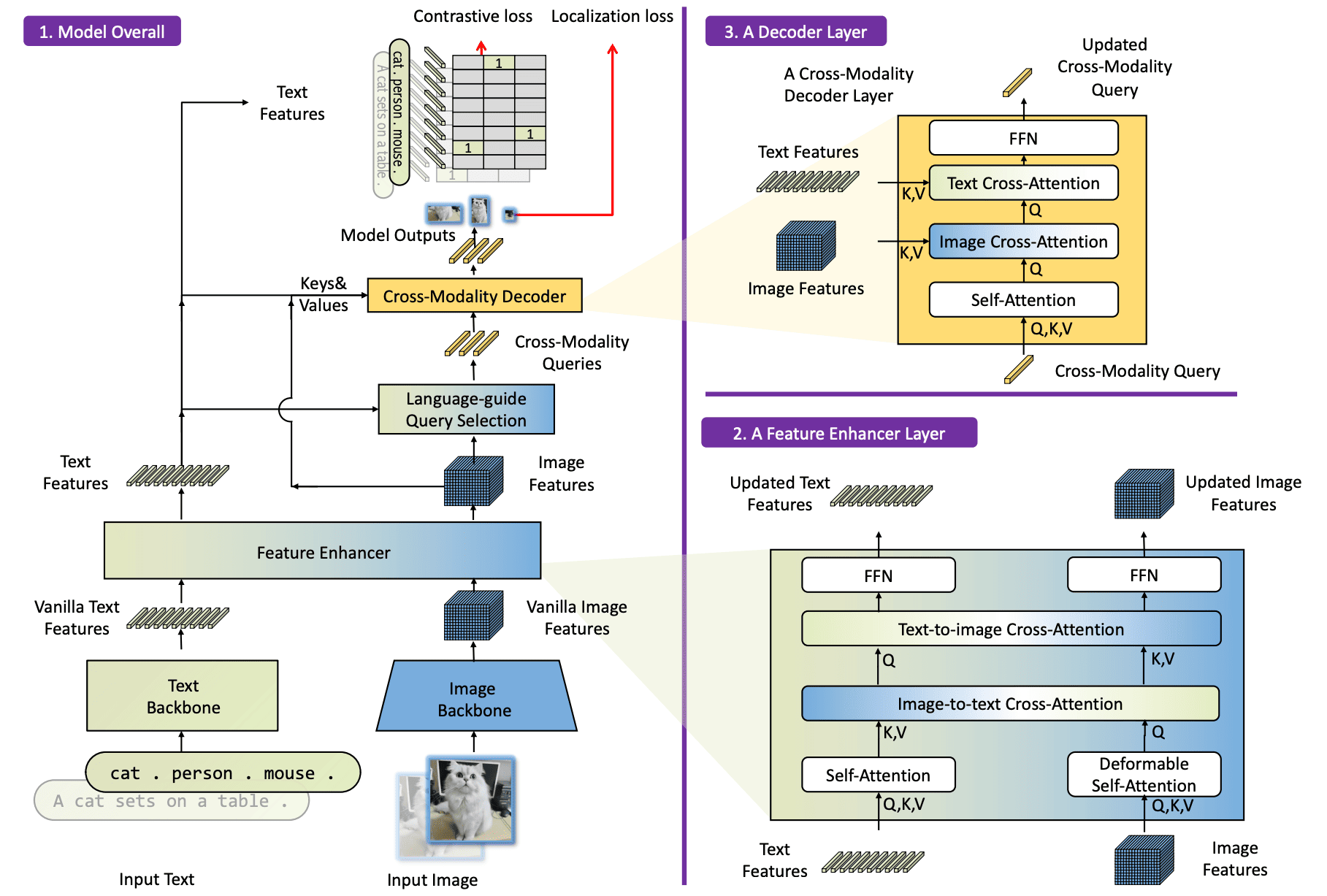
SAM 3 improves efficiency by consolidating the pipeline, moving away from the disjointed Grounded SAM approach with two separate image encoders. It takes SAM 2 and extends it with a text encoder and a detection head, allowing it to tackle the new task of PCS using a shared backbone.
The primary architectural updates are:
Image encoder. The backbone reverts from Hiera back to a plain ViT with global attention in only a subset of layers and windowed attention (24 × 24 tokens) otherwise. Specifically, SAM 3 adopts the ViT-L+ (450M) version of Perception Encoder (PE) [8], a recent multimodal model also from Meta, which is essentially a better CLIP (#7). Since this model is pre-trained on billions of image-text pairs to align vision and language, it provides the necessary foundation for identifying objects from text descriptions. This runs just once!
Text encoder. This component is the 300M param text tower of the PE model, which takes the user’s text prompt and converts it into a sequence of text tokens aligned with the image features. It is a causal transformer with a relatively short maximum context length of 32 (aka, a couple of long descriptive sentences).
Geometry and exemplar encoder. This component converts non-textual inputs into prompt tokens. The first kind (points, boxes, or masks) works just as in previous versions. The second kind is new: image exemplars, where the user draws a bounding box around an example of the concept they want, and the model finds every other matching instance in the scene. For an exemplar box, three signals are fused into a single token, which then attends to the full image through a small transformer to pick up broader context beyond the local crop and eventually gets concatenated with the text tokens into a single prompt sequence:
“Where” the box is. Via a direct linear projection of the raw box coordinates with a sinusoidal positional encoding of the center coordinates, giving the model both a learnable and a structured geometric sense of position and size.
“What” is inside it. ROI pooling crops the visual features at the box location directly from the backbone and resamples them to a fixed 7×7 grid before projecting, giving the model a rich appearance representation of the content.
A positive or negative label indicating if it is an example to match or avoid. This is simply a learned label embedding.
Presence token. One contribution of SAM 3 is this small but impactful addition. Open-vocabulary detection requires solving two conflicting objectives at once: recognizing whether a proposal matches the right concept, a global reasoning problem, and localizing exactly where it sits, a local one. SAM 3 decouples them with a single learned global presence token, which first asks whether the concept appears anywhere in the image at all. Proposal queries then only have to solve localization conditioned on that global answer, and the final detection score is the product of the two. This is especially effective when training with hard negative phrases, where the concept is simply absent. There, the presence token learns to fire a near-zero score and suppress all proposal queries cleanly.
Detector. The detection head follows the DETR paradigm. DETR [9], short for DEtection TRansformer, uses a fixed set of learned object queries, each acting as a slot that attends to image features and either claims an object or predicts nothing. To make it open-vocabulary, SAM 3 adds a fusion encoder that takes the unconditioned image features from PE and conditions them by cross-attending to the prompt tokens, making the image features aware of what the user is asking for before the object queries ever run. For custom SAM 3 finetuning (e.g. via CoOp/Prompt tuning), this can be tuned independently.
Tracker. The tracker follows the SAM 2 architecture directly (prompt encoder, mask decoder, memory encoder, and memory bank) and is trained after the detector is frozen, with both sharing the PE backbone but otherwise decoupled. This separation is important: the detector must be identity-agnostic, finding all matching instances in each frame independently, while the tracker’s goal is precisely the opposite, i.e., to maintain and separate object identities across time.
SA-Co dataset
As with every version of SAM, the data engine is as important as the architecture itself. PCS requires a fundamentally different annotation strategy compared to PVS: instead of masks tied to spatial clicks, now we need text-mask pairs. Crucially, they must be exhaustive, meaning for every concept phrase associated with an image, all matching instances must be annotated.
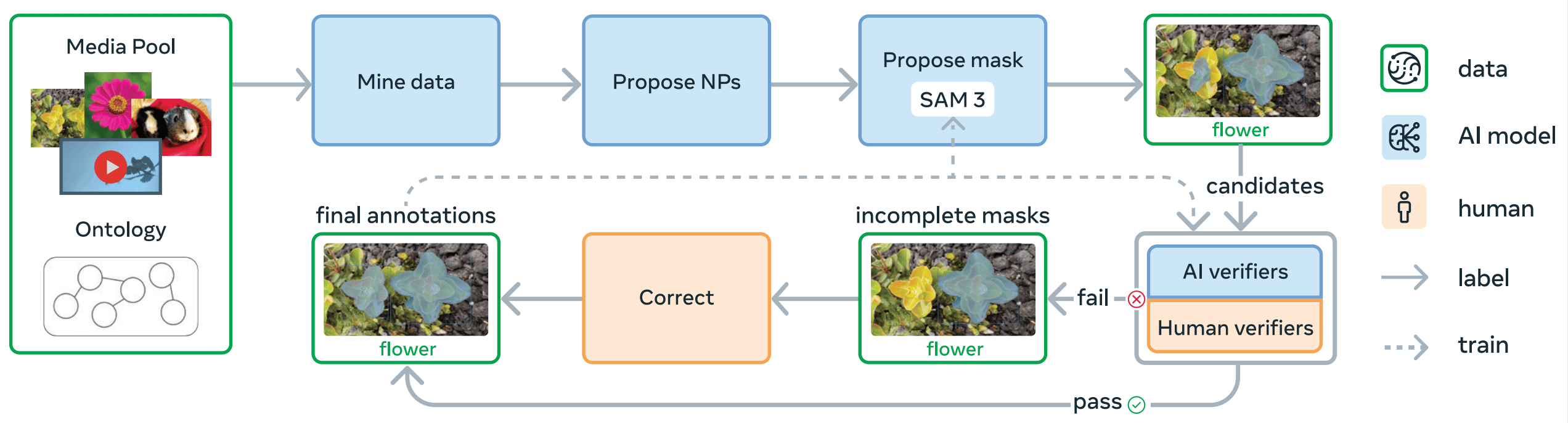
The engine runs in four phases, progressively handing off verification work from humans to AI:
Phase 1: Human verification. Images are randomly sampled, and noun phrase proposals are generated using a simple image captioner and noun phrase parser. SAM 2, prompted with boxes from an off-the-shelf open-vocabulary detector, produces the initial mask proposals. Human annotators verify these triplets, and this phase produces 4.3 million image-text-mask tuples as the initial SA-Co/HQ dataset. SAM 3 is then trained on this data and used as the mask proposal model for the next phase.
Phase 2: Human + AI verification. To scale throughput, fine-tuned multimodal LLMs from the Llama 3 family are introduced as AI verifiers, performing mask verification and exhaustivity verification automatically via multiple-choice ratings of mask quality and coverage. SAM 3 is retrained and updated six times as new data comes in, and as both the model and the verifiers improve together, a progressively higher proportion of labels are auto-generated, further accelerating data collection. Human effort is increasingly focused only on challenging cases. The noun phrase proposal step is also upgraded to a Llama-based pipeline that generates hard negative noun phrases specifically adversarial to the current SAM 3. Phase 2 adds 122 million image-NP pairs to SA-Co/HQ.
Phase 3: Scaling and domain expansion. With a reliable verification pipeline in place, the engine scales to a much broader and more diverse set of media domains. Concept coverage is pushed into long-tail and fine-grained territory by mining noun phrases from a large Wikidata ontology, with multimodal LLMs generating both the phrase proposals and hard negative candidates. For new domains, mask verification transfers well zero-shot, but exhaustivity verification needs modest domain-specific supervision to reach the same level. SAM 3 is retrained seven times and the AI verifiers three times, adding 19.5 million image-NP pairs to SA-Co/HQ.
Phase 4: Video annotation. The final phase extends the pipeline to video, with SAM 3 itself adapted to the temporal domain to produce masklets across clips. Key frames are annotated using the mature image SAM 3 and then propagated into full masklets by the video-capable model. Human effort is concentrated on the hardest cases, specifically clips with many crowded objects and tracking failures. The resulting SA-Co/VIDEO dataset contains 52.5K videos and 467K masklets.
Data summary
The result of the data engine produces what the authors claim is the largest high-quality open-vocabulary segmentation dataset to date. SA-Co/HQ covers 5.2M images across 4M unique noun phrases, forming 146M image-text-mask triplets (a high % are negatives).
To expand coverage further, the authors also create SA-Co/SYN, a fully synthetic counterpart generated without any human involvement. This scales the data up dramatically: 39.4M images and 1.7 billion image-NP pairs.
SA-Co/EXT rounds out the image side by enriching existing external open-source datasets with hard negatives via the LLM ontology pipeline described before.
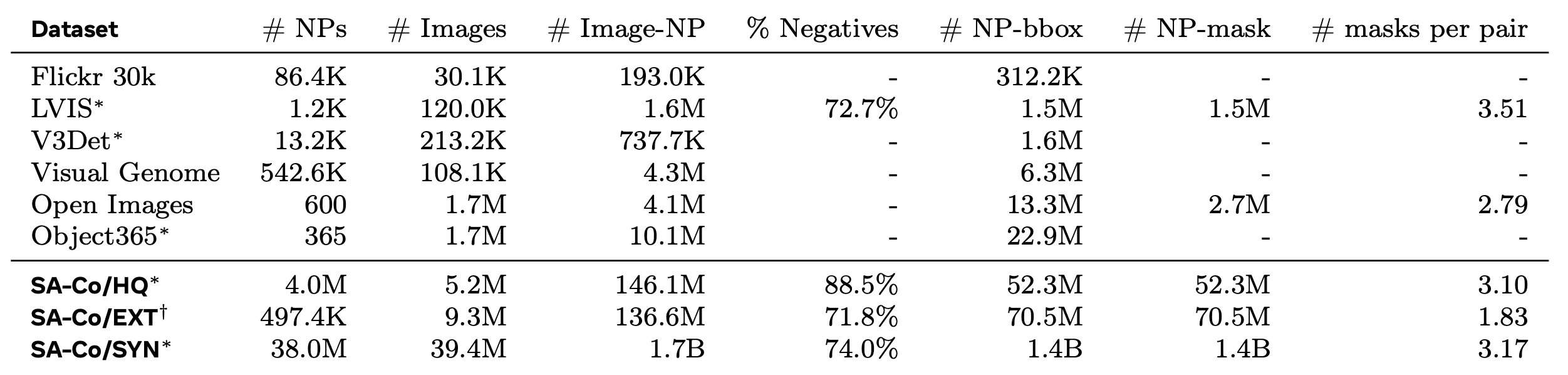
On the video side, SA-Co/VIDEO increases the concept vocabulary of existing video datasets by three orders of magnitude and is exhaustively annotated.

Hard negatives deserve a special mention. Training with phrases that describe absent concepts is what allows the presence token to learn when to fire a near-zero score and suppress all detections cleanly. For example, if an image contains fruits and oranges, a hard negative might be “tangerine” rather than “goose” or “ship”, as the first one belongs to the scene. Without hard negatives of high adversarial quality, the presence token would have nothing meaningful to learn from the negative side.
Conclusions
The arc from SAM to SAM 3 traces a clean progression: space, time, meaning. SAM established the spatial foundation, proving that a single promptable model trained on enough data could segment anything a user could point at. SAM 2 extended that across time, introducing memory mechanisms that let the model track objects through video rather than treating each frame in isolation. SAM 3 closes the loop by adding semantics: in addition to pointing, the user can describe, and the model finds every matching instance on its own.
Across all three, the data engine mattered as much as the architecture. Each version required inventing a new kind of supervision from scratch, and each time the pipeline itself got smarter, with SA-Co eventually handing verification to fine-tuned LLMs that matched or exceeded human accuracy on the task. Less human effort each time, better data each time.

Now, SAM 3 is broad enough to cover the core needs of virtually any company working in the computer vision space, which means the remaining frontier is less about capability gaps and more about depth. In a future version, I would expect a focus on improving performance in out-of-distribution domains (I can confirm it still does not segment well in manufacturing processes) and richer reasoning over what has to be segmented (maybe integrating some verifier modules). Finally, we could see some more additions regarding multimodal prompting and outputs.
SAM 3 is available for use via Hugging Face https://huggingface.co/facebook/sam3. Thanks for reading this far, and see you in the next one!
References
[1] Segment Anything
[2] SAM 2: Segment Anything in Images and Videos
[3] SAM 3: Segment Anything with Concepts
[4] Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
[5] Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
[6] Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
[7] DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
[8] Perception Encoder: The best visual embeddings are not at the output of the network